Working with high-frequency market data: Data integrity and cleaning

We're kicking off a multi-part series on using high-frequency market data. In part 1, we focus on data integrity and cleaning, sharing a brief background of the existing literature on cleaning market data and how this often doesn't relate to modern market data infrastructure.
A few key areas we cover are exceptions to when to clean your data, how cleaning can lead to data degradation, and effective strategies for data quality assurance.
Before we dive in, let's define a few common terms and concepts.
High-frequency market data is often characterized by high granularity and large volumes of data, broadly referring to any full order book data (sometimes called "L3"), market depth (also called "L2"), and tick data (sometimes called "last sale"). Because these terms tend to be used interchangeably without a clear convention, we refer to these as "MBO (market by order)," "MBP (market by price)," and "tick-by-tick trades," respectively.
We'll start with a hot take: Don't clean your market data.
Much of the public literature on market data cleaning and integrity cites prior work by Olsen and Associates's crew, who published their approach on "adaptive data cleaning" in An Introduction to High-Frequency Finance (2001).
One of the top Google search results on "cleaning tick data" yields an article titled "Working with High-Frequency Tick Data," which suggests removing outliers and cites outdated practices on Brownlees and Gallo (2006). This paper, in turn, cites Falkenberry's white paper (2002) for tickdata.com, which recurs back to Gençay, Dacorogna, Muller, Pictet, and Olsen. Later publications as recent as 2010 still refer to these methods. While these approaches make sense academically, they differ from best practices in actual trading environments.
What these adaptive trading filters often consider to be "outliers" are false positives—examples of actual trading activity that we want to keep. We'll suggest some better ways of handling this.
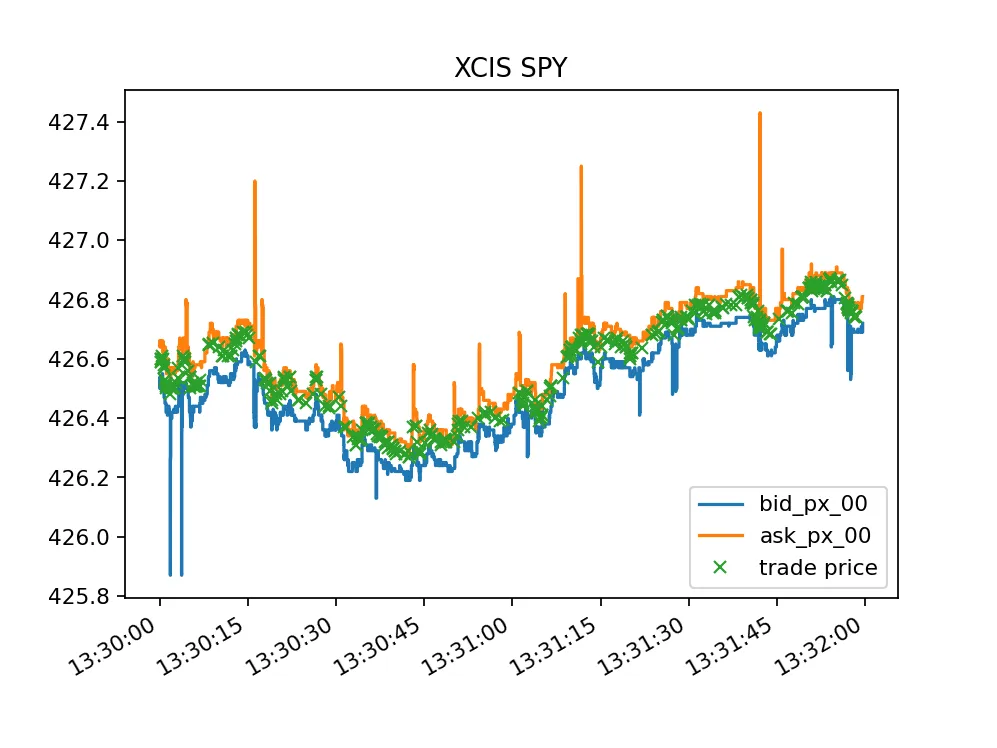
Here is an example of actual trading behavior: SPY on NYSE National's prop feed. Outliers and significant dislocations in BBO are commonplace even on widely traded symbols on less liquid venues. Extracted from Databento Equities Basic.
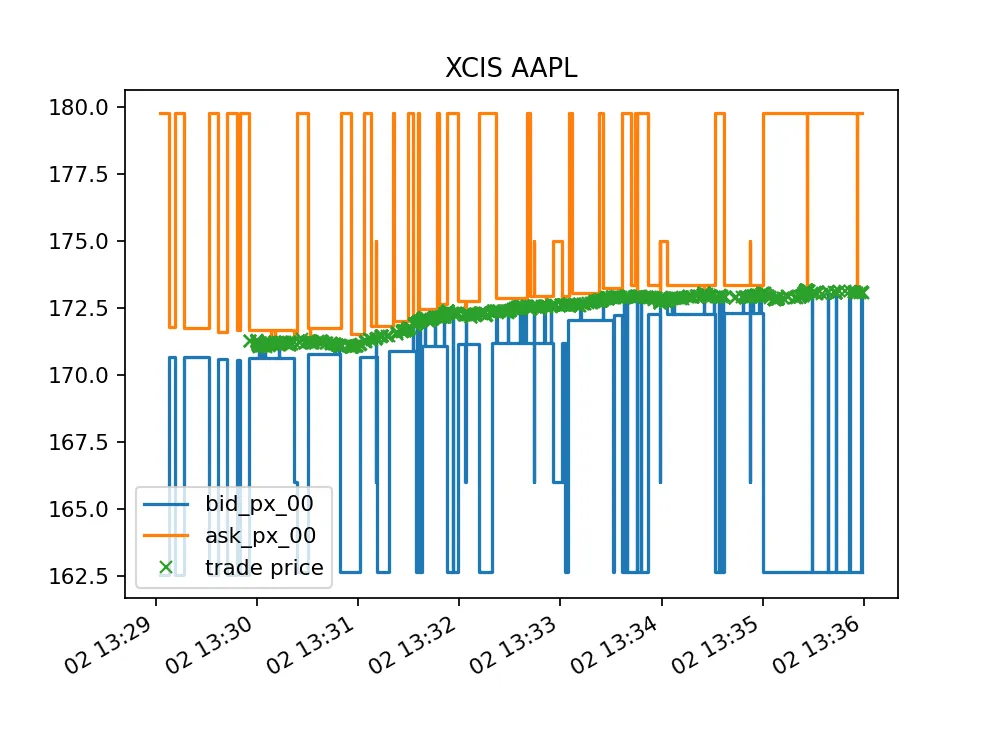
Here is another example of actual trading behavior: AAPL on NYSE National's prop feed. The BBO fluctuates with a different, more deterministic pattern. Extracted from Databento Equities Basic.
It's important to know a few things about modern market data infrastructure to understand why it's unnecessary to clean market data these days.
- Raw feeds and direct connectivity are often overprovisioned, so you rarely have packet loss if your infrastructure is correctly set up downstream of the venue handoff.
- Modern feeds and matching engines are usually well-designed enough that the days of spurious prints are long gone. Most of the academic literature and white papers on cleaning tick data and real-time filters for tick data errors are based on the behavior of older iterations of the SIPs and matching engines.
- The widespread adoption of electronic trading in the last two decades has mostly squashed tick data anomalies. Any bug in the raw feeds invites microstructural exploits that quickly get reported. Participants thoroughly scrutinize any edge cases, matching scenarios, sequencing, and timestamping issues so they're uncommon.
- Many trading venues use white-labeled versions of more mature trading platforms from larger market operators like Nasdaq (e.g., J-GATE), Deutsche Börse, Currenex, etc. So, pricing data errors from poorly implemented matching engines have become less common.
- Checksumming and other practices are in place to prevent silent bit rot and other physical events that cause price anomalies.
That said, there are exceptions where it's important to scrub and clean your market data:
- If you're using a data redistributor that provides a very lossy normalized feed or is known to mutate the raw data silently, the benefits of scrubbing the data could exceed the downsides.
- If you primarily trade in OTC, open outcry, auction markets, or more exotic trading venues with outdated infrastructure (e.g., a UDP unicast feed with no recovery mechanism), it's still essential to clean the data.
- If you're using non-pricing data that requires manual data entry or scraping, such as financial statements, SEC filings, corporate actions, etc., it's often better to scrub the data and preprocess it upstream of your application logic so you don't have code repetition.
- If you're using low-resolution market data from a redistributor with an opaque process for subsampling. In that case, this can be prone to errors introduced by the vendor that are otherwise not present on the direct feeds.
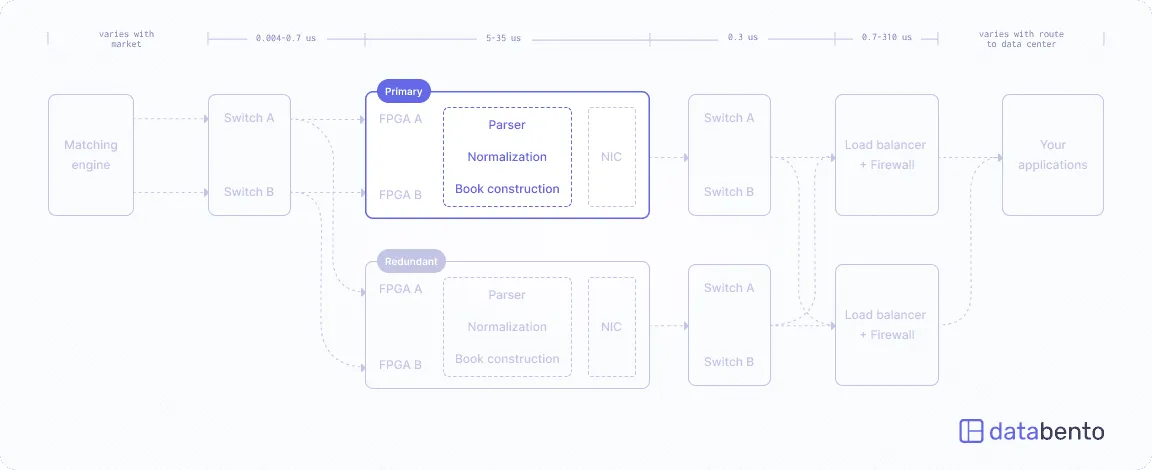
Databento architecture: We generate all the low-resolution and subsampled data, even daily OHLCV aggregates, in one step on the same server that ingests and parses the direct feeds to ensure consistency.
"Any bug in the raw feeds invites microstructural exploits quickly get reported away. Participants thoroughly scrutinize edge cases[...] so they're uncommon."
Proprietary trading firms quickly test new feeds, protocols, and connectivity. You'd be surprised how fast bugs get caught in the direct feeds when significant amounts of daily PnL are on the line.
One reason we pulled together Databento's core team from various prop trading firms is that it takes a specific team culture and patience to chase these issues down to the venue side—and it's hard to instill this with people who haven't had production trading experience.
The more important reason to avoid "cleaning" your data, in the conventional sense, is that the cleaning process almost always degrades the data quality.
- Ex-post cleaning introduces desync between real-time and historical data. Most "data cleaning" strategies are applied offline on a second pass of stored historical data. This is the worst kind of data cleaning because it introduces a desync between the historical data you're analyzing and the real-time data you'll see in production. If your data provider advertises that their data is scrubbed for errors and touts their data cleaning techniques, or if you report missing intraday data to your provider and suddenly it's quietly patched, they're probably guilty of this antipattern.
- Anomalies are usually "true" behavior. If you have a lossless feed (no sequence gaps), any remaining gaps are likely accurate. You typically want to see these anomalies because they are real and affect many other trading participants, and you want to take advantage of them. Examples include times when the source feed fails over to their disaster recovery site. What better time to be quoting a wide spread than when most participants arbitrarily refuse to trade because of their tick data filters or operational risk mitigations during a feed failover?
- Real-time or adaptive filters have non-determinism that is very difficult to replicate in simulation. Even if you're applying "cleaning" inline on real-time data, it usually imparts non-deterministic latency and other effects that are hard to replicate in backtest or simulation.
Before considering cleaning your market data, try these recommended strategies first.
- Build robustness in your trading model or business logic. For example, truncating or winsorizing your features can be done constantly and improve model fit. It's better to leave the decision of what's an "anomaly" to downstream application logic, e.g., your trading strategies. Taking this point to the extreme, it's better that your data has errors because it forces you to write explicit trading strategy behavior to handle data errors and events like gateway failover.
- Systematically fix bugs and address normalization edge cases. If you see spurious prints and anomalies, it's better to systematically fix any parser bugs or address normalization edge cases that are most likely responsible. It's also often better to do a complete regeneration of history after fixing those bugs than to do surgical patches of specific days of data to ensure consistent data versioning.
- Perform internal consistency checks. Rather than looking at values, construct book snapshots, convert market-by-order (MBO) to a level book with aggregated depth (MBP), compute OHLCV aggregates from incremental trade events, and compare them to the session statistics messages provided directly by the trading venue.
- Report anomalies to the trading venue rather than address them in your code. In rare cases, you see a recurring bug that the venue needs to fix. This is one of the reasons we include the original sequence numbers and channel IDs in Databento's normalized data—it allows you to work directly with the trading venue on trade breaks, matching errors, and data issues.
- Fix inconsistent book states by marking them with flags. This is preferable to discarding data altogether. At Databento, we use bit flags like
F_BAD_TS_RECVandF_MAYBE_BAD_BOOKto indicate this. Out-of-order events and missing data may be self-healed with "natural refresh." Natural refresh is a common strategy adopted by low-latency trading systems that want to avoid paying the cost of A/B arbitration or gap retransmission. For example, if you see a cancel message for an order IDnthat you've never seen before, you could assume that you missed the original add message for order ID n, but that has now been self-corrected. - If you have to use a distributor's normalized feed, pick a data provider with strong data versioning practices, write their own parsers, and trace the provenance of the data back to the original raw packets. We address data versioning at Databento with an API endpoint to get dataset conditions and last modified dates, plus a public portal for reporting data errors.
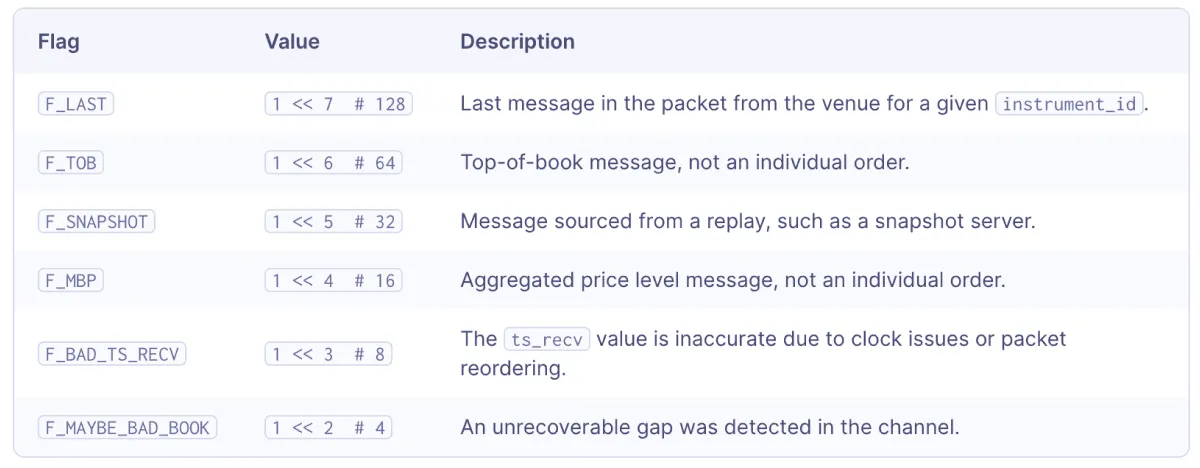
Examples of Databento bit flags.
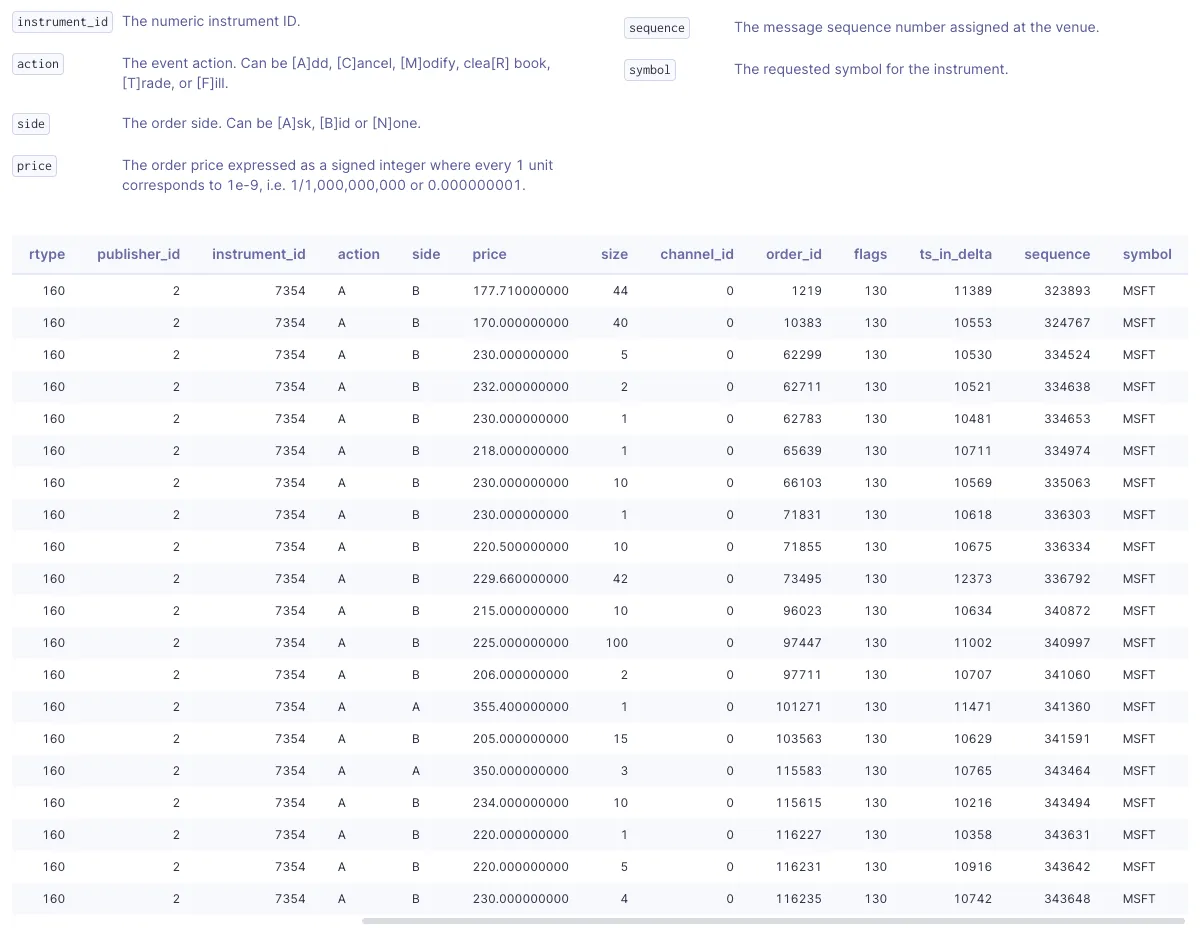
We embed the original sequence numbers and channel IDs where available, so that you can interact with trading venues' support desk and sequence order execution events.
In part two of this series, we'll talk about white labeling, the hidden implications of data integrity, and more best practices for performing checks on data integrity.