What are market data schemas?

Market data schemas (or "formats") are essential for organizing and interpreting financial data. However, inconsistencies in naming conventions among different market data vendors have caused confusion over the years. In this blog post, we aim to clarify what market data schemas are and provide an overview of the schemas supported by Databento.
A market data schema refers to a standardized format for organizing and representing different types of market data. It consists of a collection of data fields that define the structure and content of the data records. Schemas play a vital role in ensuring consistency and compatibility across financial systems and applications for efficient data processing, analysis, and utilization.
Our datasets support multiple schemas, such as order book, tick data, bar aggregates, and so on. You can find a detailed list of fields associated with each schema in our documentation.
Databento uses the following naming conventions for the market data schemas supported on our platform:
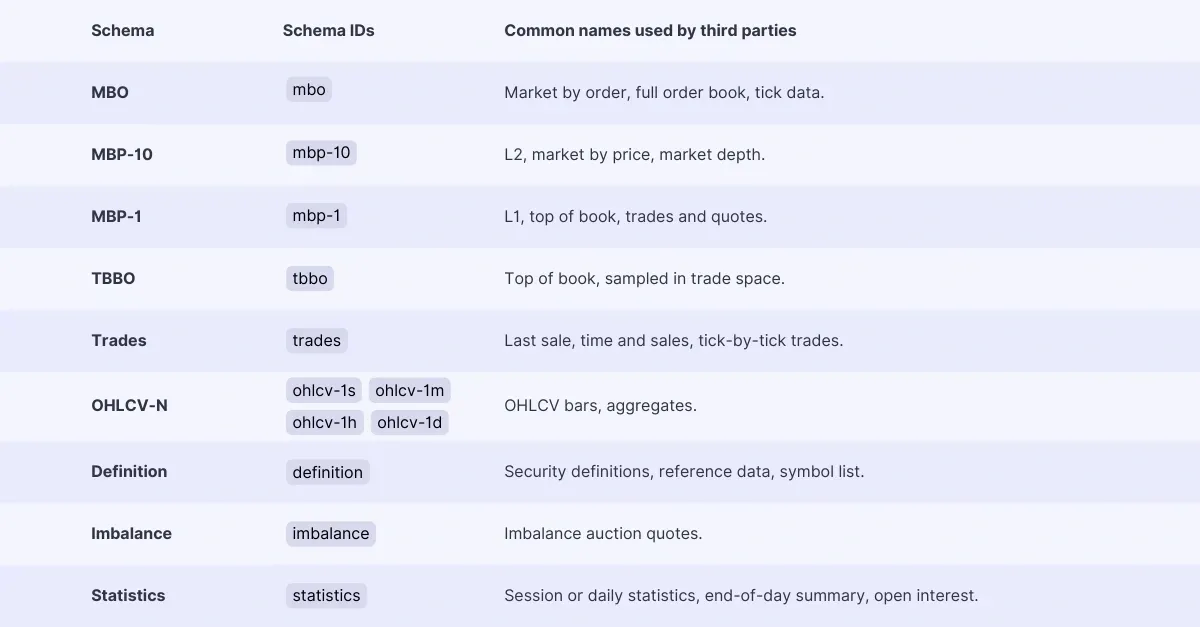
MBO provides granular information for each individual order event, identified by its order ID. MBO offers the highest level of granularity, making it valuable for in-depth analysis.
MBP provides changes to and snapshots of aggregated book depth, categorized by price. This schema represents a fixed number of levels from the top of the book. We denote the number of levels in the schema name, such as mbp-1 and mbp-10, to indicate the level of detail.
TBBO provides individual trade events combined with the best bid and offer (BBO) immediately preceding each trade. It differs from MBP-1, as TBBO includes non-trade events that modify the book depth at the BBO.
Trades includes every individual trade event, providing a comprehensive record of executed trades.
OHLCV provides data at regular time intervals, including opening, high, low, and closing prices, along with aggregated volume. Suffixes like ohlcv-1s, ohlcv-1m, ohlcv-1h, and ohlcv-1d represent 1-second, 1-minute, 1-hour, and 1-day intervals respectively.
Definition provides instrument details such as symbol, instrument name, expiration date, tick size, and strike price, enabling accurate instrument identification.
Imbalance provides auction imbalance data, including paired quantity, total quantity, and auction status.
Statistics provides venue-specific instrument statistics data. This data may vary across datasets, but generally includes information such as daily volume, open interest, and opening/closing prices. Databento doesn’t compute any statistics, and all data is provided by the venue.
Note: We categorize any data event that modifies the state of the order book as a "book event." This term applies to all the schemas mentioned above, as they represent changes to the order book's state.
To ensure clarity and consistency, we avoid using terms like Level 1, Level 2, or Level 3 market data, as their application varies across different vendors. Instead, we adhere to naming conventions that accurately represent the schemas. For instance, some vendors refer to both MBO and MBP data as Level 2 market data, which can cause confusion. We also refrain from using the term "tick" to refer to resting limit orders, as it traditionally pertains to trade data.
We also avoid the term "quote" to prevent ambiguity. While it originates from the concept of requesting a quote from a broker, vendors have different interpretations of whether resting limit orders outside the best bid and offer should be counted as quotes.
Here are our supported schemas listed alongside common names used by third parties:
We use the term order to refer to any incoming order that may subsequently be matched, canceled, rejected, or posted to the order book. If the context is unclear, we use the term resting order to distinguish the last type. Despite this naming convention, we recommend using the term quote to refer to the data structure for an order when you are integrating MBO data into any trading application.
This recommendation is a contravention of the standard use of the term and may even result in unpleasant variable names like quotebook. However, this is a good practice if your application also needs to send and manage orders. If you reuse the term order when interfacing with both data and order execution, your code will likely become less manageable as you will have very different objects called "orders" in the same namespace.
Consider the situation where you are building a market simulator for backtesting a passive strategy. Your strategy listens to public order events, builds an order book, sends orders, and tracks those orders in an order management system. Furthermore, your market simulator also builds an order book and matches your hypothetical orders against resting orders from the historical data. The market simulator also has to privately report fills of your hypothetical orders to your strategy and publish your filled orders in the simulated public data feed.
While market data schemas generally adhere to consistent naming conventions, there are specific scenarios that require additional consideration. Let's delve into these special cases and how they may impact data interpretation:
Raw data from US equity Securities Information Processors (SIPs) represents a unique form of MBP schema. It consists of MBP-1 data from multiple markets, resulting in a consolidated book with multiple price levels. When a user requests MBP-10 data from a SIP dataset, it indicates a desire for 10 levels from the consolidated book.
The ITCH protocol is widely used for direct feeds with the MBO schema. However, certain foreign exchange (FX) Electronic Communication Networks (ECNs) utilize ITCH dialects that key data by price, thus employing the MBP schema as their primary structure.
Typically, MBO provides the highest level of granularity. However, certain markets offer separate trades feeds that include additional information beyond the MBO feed. This can include trades not displayed in the MBO feed or artificially delayed MBO data. In such cases, we document the exception and recommend subscribing to both MBO and trades feeds for those seeking the utmost level of granularity.
These special cases require attention to ensure accurate data interpretation and integration. By understanding the nuances and variations in these scenarios, users can make informed decisions when selecting the appropriate schema for their specific needs.
When first getting started with our data, it's helpful to check out our list of fields by schema and read about best practices for exporting schemas.
