Using the same code for seamless backtesting to live trading
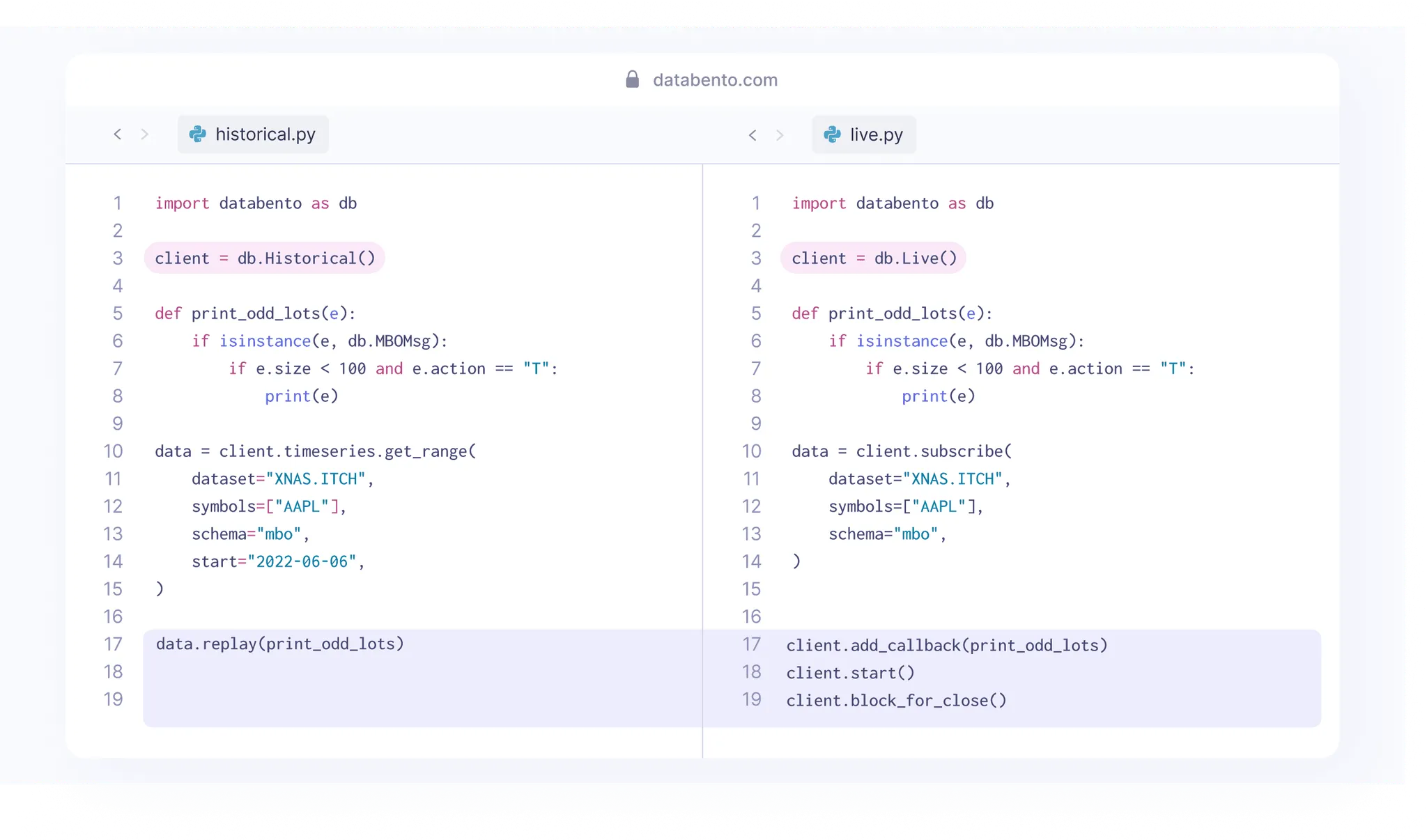
One of the most essential features of a market data API for a systematic trading platform is using the same code for backtesting and live trading. Market data vendors often advertise claims like "data quality," "rows of data," "reliable," and "fast" but don't address matters that improve actual trading workflows.
Many vendors are missing market replay functionality, have different formats for historical flat files and real-time data, and have differences between their historical and real-time interfaces.
Integrating their APIs propagates the problem to your platform and makes it hard to design effective interfaces to harmonize backtesting vs. production.
Using the same data format for historical and real-time data allows your strategy to be implemented only once. It doesn't have to port over from Python/MATLAB/R to C++. The strategy calls the same interfaces, and the same configs/meta-configs are reused for prod deployment. These features speed up your production cycle.
Additionally, it reduces second-guessing if OOS performance is worse due to model overfit, covariate shift, software bug, or implementation error in your simulator or ported strategy.
It also saves valuable time for quantitative researchers, developers, and engineers, which is more expensive than your infrastructure. If your backtesting engine is slow, you can always throw more IO or compute at the problem, but scaling human resources is much more challenging.
At Databento, we make it easy to integrate and design an effective interface by having a zero-copy binary format that's identical for both historical and real-time data, exposing a market replay method in our clients that emulates real-time, and supporting intraday replay in our real-time API so you can burn in your signals directly without stitching historical data to real-time. We also deliberately designed our historical and live APIs to look identical.
Learn more about our historical and live market data APIs on our docs page.
