Why exporting inline is critical for high-quality market data
Exporting inline is critical if you want high-quality market data. Yet few data providers offer this feature—despite the extensive issues exporting inline can address. In this article, we'll cover some key benefits to exporting inline (and some consequences if you don't) and share some common challenges to implementing inline exporting and why we think it's still worth the effort.
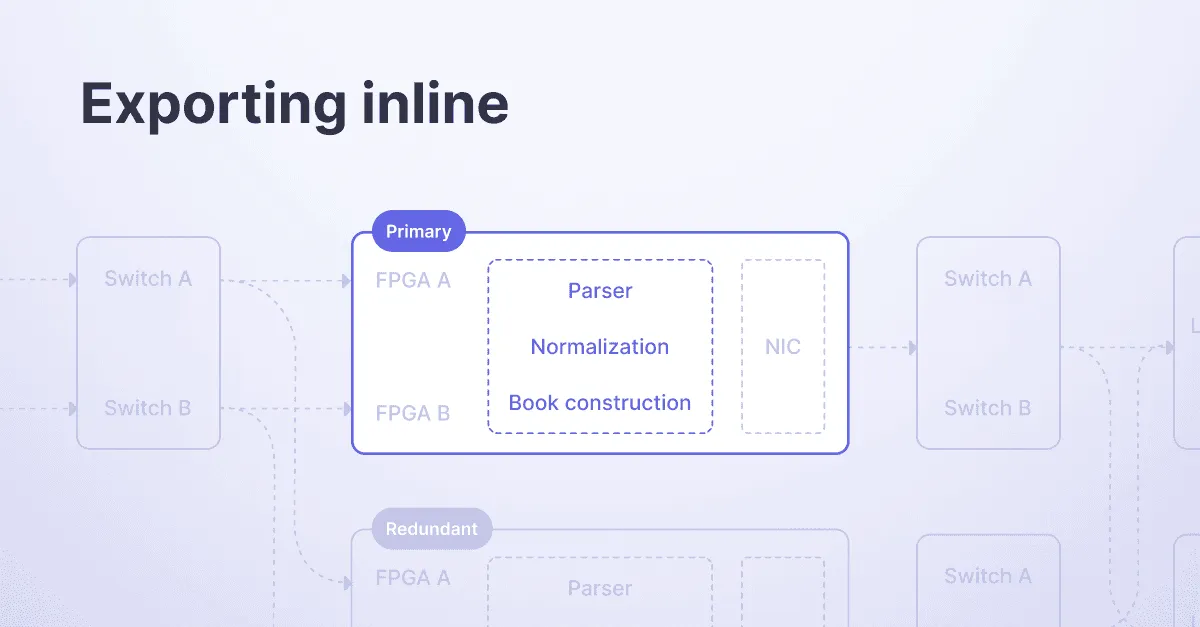
First, let's talk about exporting inline in general and how we do this at Databento.
What we do differently at Databento is export all derived formats, like MBP, last sale, and OHLCV aggregates, from the order book data (or whichever format is the highest granularity from the direct feed). All of it is generated inline, on the same application that decodes the raw packets in real-time. Done together, we call this "exporting inline."
We perform historical backfill similarly—replaying the packets through our real-time processing application that does parsing, normalization, and exporting.
In addition to providing the most accurate, highest-quality data, exporting inline has several additional benefits.
Some will only provide you with one or two formats and leave it to you to export the other formats or resample the data. The few that give you several formats often export them separately and are usually plagued with the following issues:
- Inconsistency between data formats: For example, if you sum up the trade volume from the tick data for a minute and it doesn't match the trade volume on the 1 min OHLCV aggregate exactly, it's difficult to know which you should trust.
- Misaligned executions: The quotes are timestamped asynchronously from the trade feed, so the trades hardly ever print within the BBO.
- Misaligned timestamps: When trade timestamps on the order book or tick data don't match those on lower-frequency or subsampled data.
- Inconsistent book state: e.g., real-time BBO updates are out of sync from price level trade-throughs.
- Inline data generation can quickly catch bugs in our code and gaps in the data. For example, generating the BBO and book snapshots is a very stateful operation that will usually complain if there are inverted spreads, executions of missing order IDs, etc. Running these checks further downstream is possible, but it's generally better to catch data errors earlier in the process.
When implemented correctly, this usually means the same thread, or pool of threads, is decoding the network packet and generating exported schemas like OHLCV; there's less overhead in unnecessary network hops, message passing, copies, and I/O.
One of the reasons our support team gets rave reviews is that we can quickly correlate events on the low-granularity, subsampled formats against the order book data and raw packets. We know the triggering message sequence number for each daily bar print, enabling us to provide support quickly and effectively.
We've heard from customers that other market data providers aren't able to investigate any inconsistencies with their data, leaving users out of luck and with no explanation for the differences.
It's interesting to understand why other data providers don't do this because it yields some useful engineering lessons.
In the rare case where a customer finds a bug that only appears to affect one data format, we often regenerate everything to patch the data while ensuring consistency. This takes a long time. In one extreme case on CME, we processed petabytes of PCAPs to correct an issue that only affected several days of data.
If you report a data quality issue to your provider and it's patched the same day, take note. This could mean they're just patching specific dates ad hoc and not addressing the problem's root cause across their entire coverage. More importantly, it's likely that they'll fix one format and not the other, leading to more inconsistencies and a cascade of data provenance and versioning issues. The way we mitigate the wait time is to expose an API that provides metadata on the condition of the data. For example, data could be flagged as degraded if known issues exist.
Our approach of exporting derived formats inline requires us to get the highest granularity of data for each venue—which is expensive as we're paying colocation and direct access fees for every venue. This usually starts at around $10,000 monthly recurring costs and license fees.
Understandably, many market data providers cut costs by white labeling or redistributing from another data provider rather than sourcing data directly from the trading venue. One way to verify this is to check the official list of data distributors on the venue's website, though not all venues provide this.
Another practice we've seen is that some data providers mix and match different sources for different formats, resulting in inconsistencies between formats.
Higher-quality data will naturally cost more. Depending on your use case, it may or may not be worth the investment. That said, as a startup ourselves, we understand budget restrictions and offer multiple pricing plans to make even our most granular data accessible.
Processing trades, quotes, and every other format on separate servers is another pattern we've seen with other market data providers. This is usually because their processing application or normalization is poorly implemented or too slow.
Our feed handlers are generally capable of processing all incoming messages at line rate, with plenty of resources to spare, so a monolithic application that exports the derived formats inline makes more sense.
That said, inline exporting is more practical to implement. An application that handles multiple formats simultaneously is susceptible to random access patterns, cache incoherence, and pointer chasing. If you're writing out all of these formats to disk at once, there's a good chance you're hitting your storage system with random IO.
If any of the challenges we mention in this article sound familiar, it's probably a good idea to look at how your market data provider is sourcing and formatting the data you access. If inline exporting isn't offered, that may be a sign you aren't getting the best data for your investment.
Check out our documentation to learn more about how Databento handles inline exporting.