Why we didn't rewrite our feed handler in Rust
We recently faced an interesting decision: what language should we use to rewrite our market data feed handler? Despite Rust's growing popularity in fintech and our own successful use of it in other systems, we chose C++. This post explores the technical reasoning behind that choice, diving into specific patterns where Rust's strict ownership model created friction for our use case.
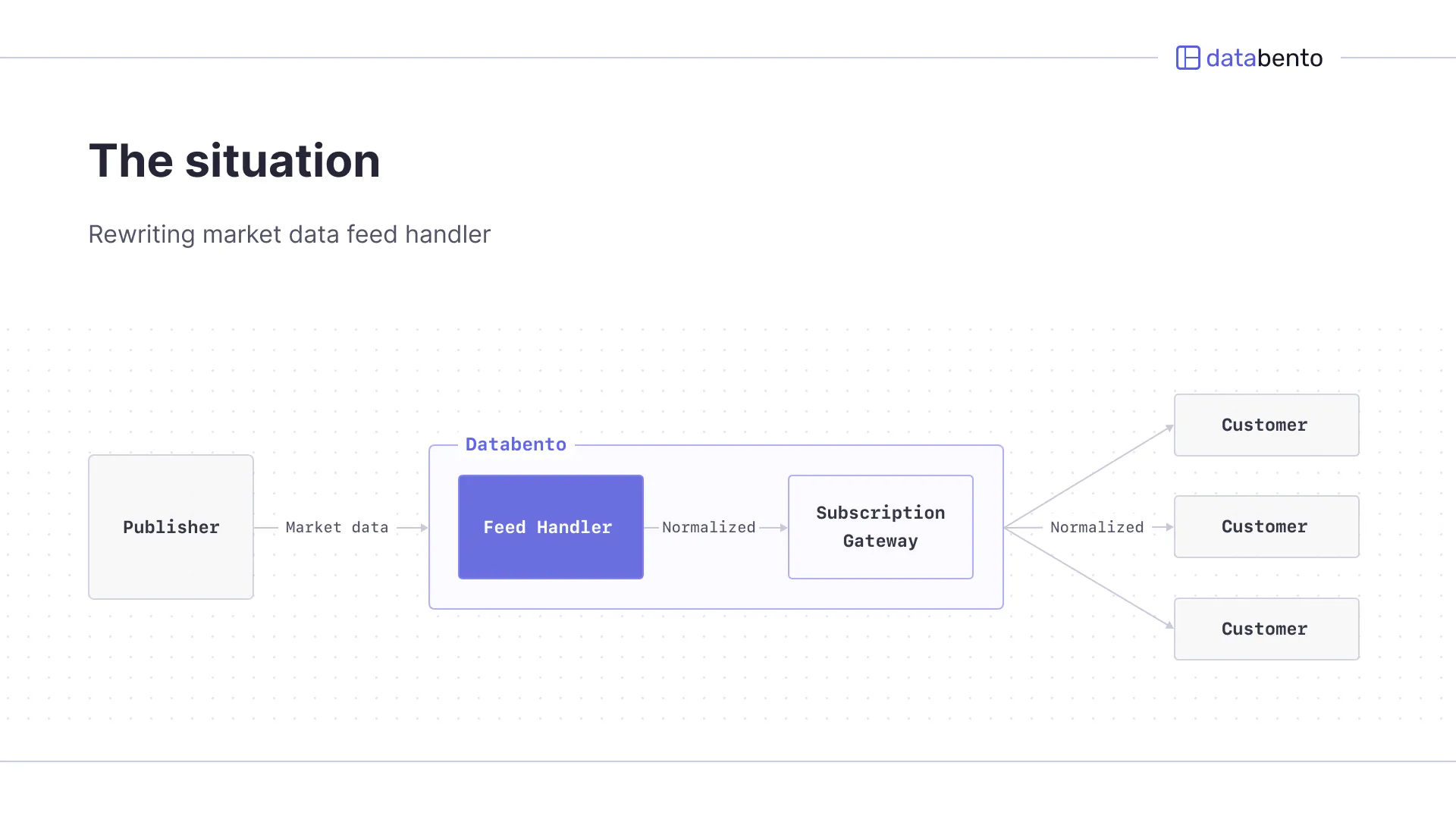
Our real-time market data architecture processes 14 million messages per second with sub-100 microsecond latency requirements. At its heart sits the feed handler, a colocated application that parses proprietary feeds from exchanges and normalizes them to our DBN format.
The existing implementation had accumulated technical debt over time. It was overly generic, supporting workflows we didn't actually use. The architecture wasn't modular enough, which made optimizations invasive and difficult. Most critically, it had a complex concurrency model that led to a lot of context switching, and an abundance of shared state resulted in lock contention where spikes in one area could cascade across the application.
Given these issues inherent in the architecture, we decided a rewrite was the best path forward. Our new implementation needed to:
- Keep things simple with minimal shared state and basic parallelism while avoiding premature optimization
- Have a narrow focus and outsource as many tasks as possible to other services (like calculating OHLCV bars)
- Be fast enough to handle our 14M messages/second throughput with predictable sub-100μs latencies
A language that compiled to native code was non-negotiable.
We weren't starting from zero with Rust. At Databento, we've successfully deployed it across several critical systems:
- The reference implementation of our DBN encoding, which also handles serialization to CSV and JSON
- Our real-time market data gateways (the other colocated service that clients connect to)
- Our official Rust client library, a top 10 most downloaded crate in the finance category
- Python bindings for performance-critical functionality
Rust brings compelling advantages. The built-in tooling through cargo makes it much easier to get started with a greenfield project. There's a simple build system, integrated dependency management, a test harness, and you can generate documentation from comments in the code. It sharply contrasts C++, where, for instance, dealing with CMake is such a persistent frustration that most of us would be happy to never have to use it again.
While Clang and GCC have come a long way, Rust's compiler errors are still on another level. They're especially helpful when first learning the language and when dealing with the ownership model. Sometimes it even suggests a fix, and this all speeds up the development process.
For finance applications, Rust's design for safety and correctness is particularly appealing. It prevents entire classes of bugs, including uninitialized data, lifetime errors, and data races.
There are three places where we've fought the Rust compiler in the past. These experiences colored our language choice for the feed handler.
Rust's compiler is known for being strict. It often guides you toward better, more correct solutions. However, the ownership model is exactly that—a model. It can't understand all safe patterns.
Sometimes it rejects safe patterns that don't align with the model. Let's look at specific cases where Rust made things more difficult or outright prevented our preferred design.
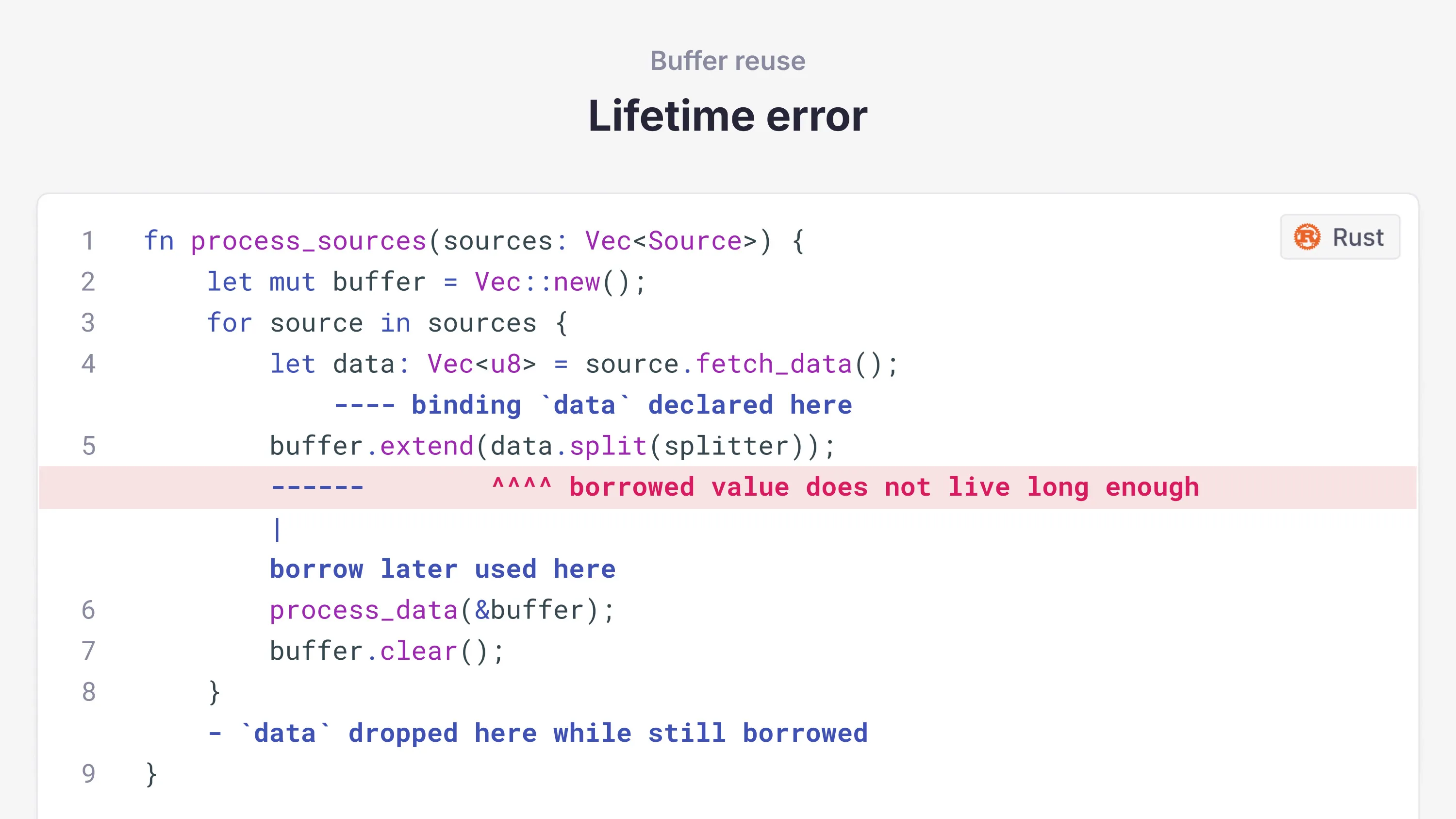
A common optimization when reading large amounts of data is buffer reuse. You read some data into one location in memory, process it, then read the next chunk into the same memory location, reducing allocations. When trying to eliminate copies by passing around references in Rust, you end up with lifetimes. Unfortunately, when these two come together in Rust, they can clash.
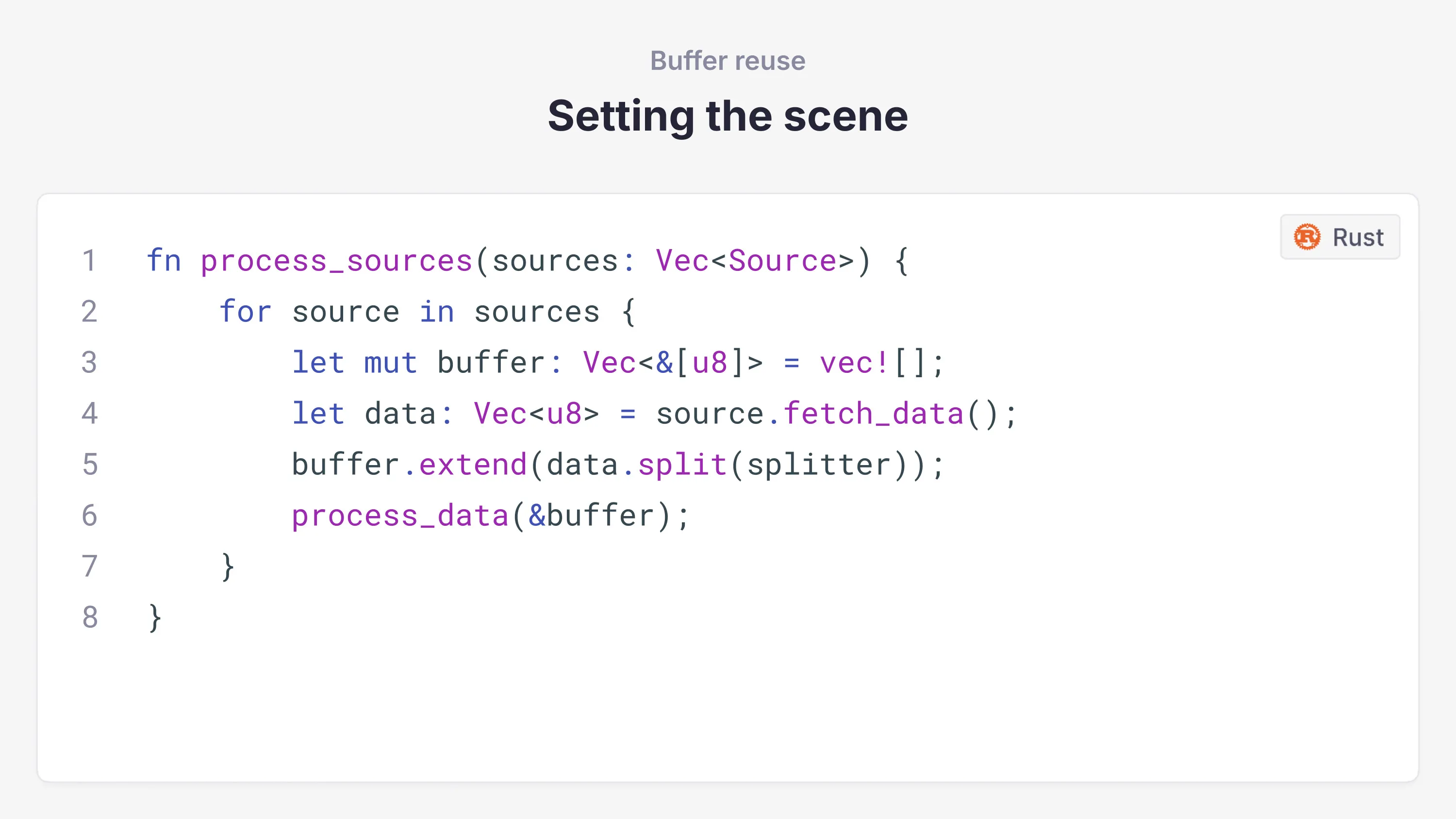
Consider a simple optimization where we move buffer allocation outside the loop to reuse it across iterations:
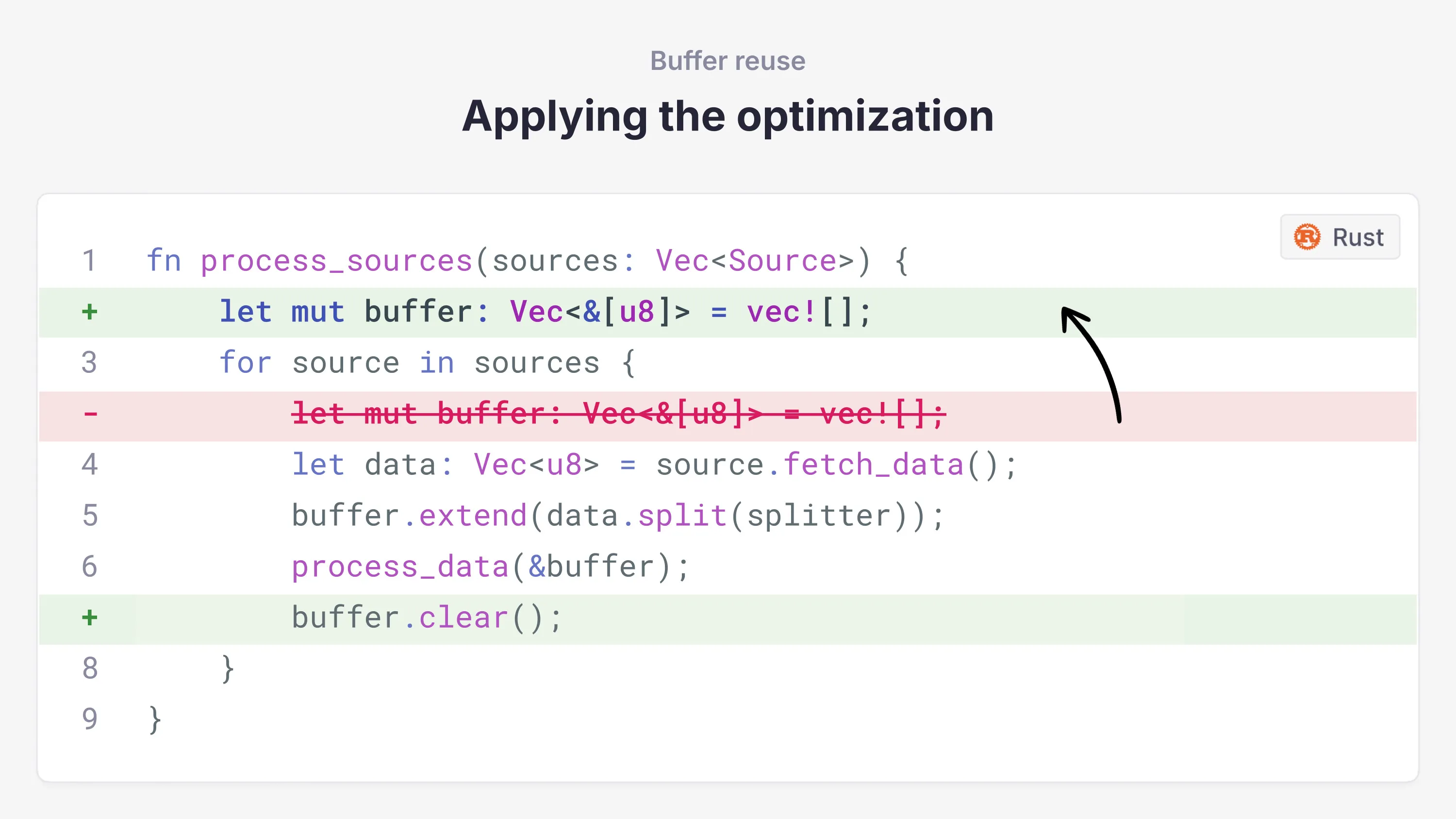
This fails to compile. Rust wants to prevent use-after-free bugs, and so it tracks the lifetimes of references. Because the local variable data is created within the for loop scope, which has a shorter lifetime than buffer, Rust rejects it. The borrow checker isn't sophisticated enough to understand that the buffer's contents never outlive the scope of a single iteration because we always clear it.
In C++, the equivalent code compiles fine. The trade-off is you have to track the lifetimes of references manually, as the compiler won't catch legitimate use-after-free bugs for you.
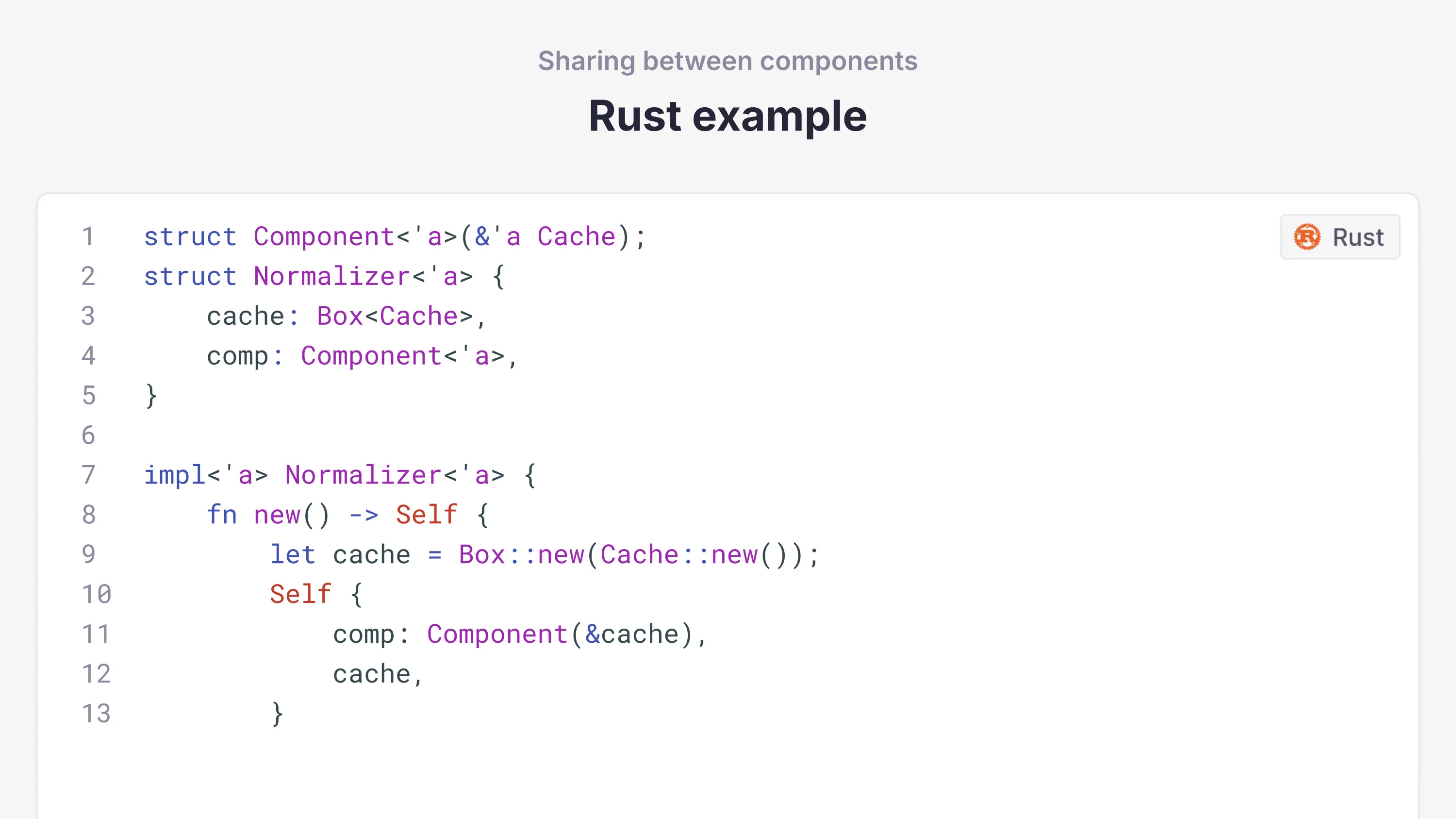
Another common pattern is to have state shared between multiple subcomponents of a class. Usually, the class itself owns the state, and then the subcomponents hold references to it. This technique helps modularize logic, making the primary class easier to understand.
In Rust, this is known as a self-referential struct—the comp field references the cache field. This pattern doesn't work well in Rust's borrowing model:
Even when we box the cache to give it a consistent memory location (Rust doesn't have move constructors), the compiler still considers it a local variable and prevents returning a value referencing it:
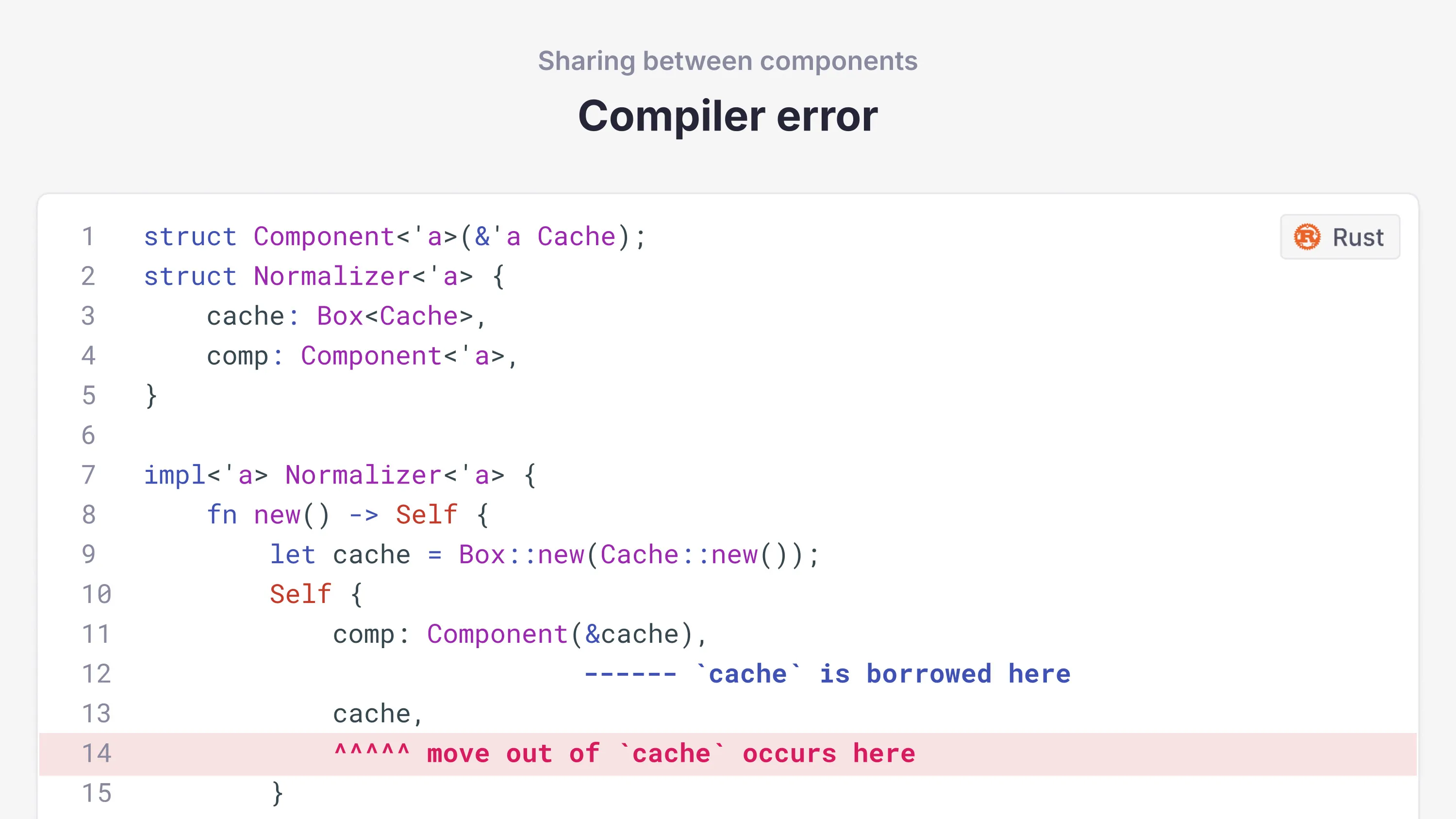
The Rust way around this is to use reference-counted pointers (adding overhead) or pass the cache as an argument to every method that needs it (not always ideal).
In C++, we simply declare _cache before _comp so it's initialized first, then initialize the component with a reference to the cache member variable:

This compiles fine without needing to put the cache behind a pointer, although to flesh this out, we'd want to follow the rule of five and delete or define the move and copy constructors so the component won't be left with a dangling reference if it's moved.
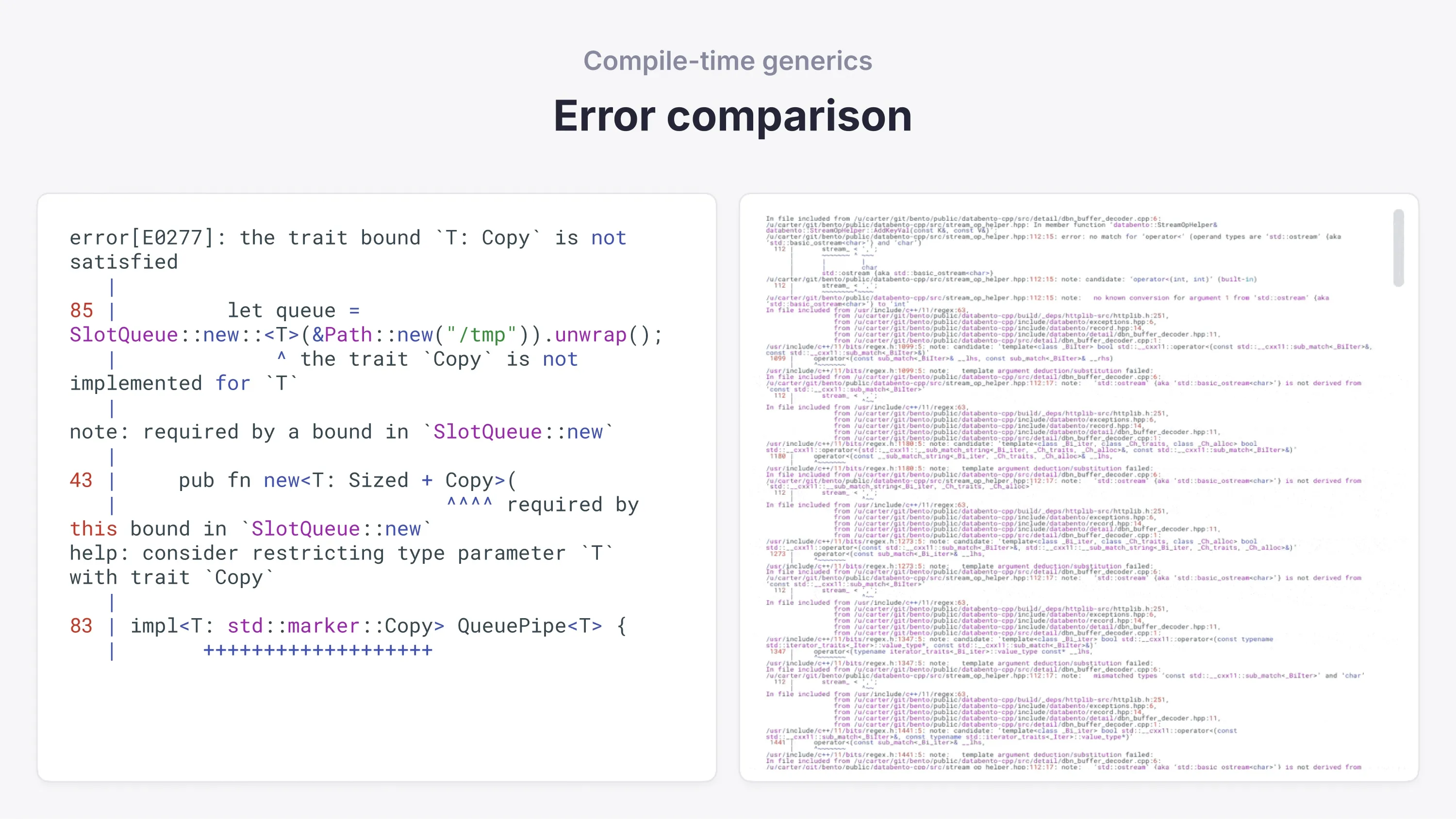
Compile-time generics are crucial for code reuse as they allow you to write code that's generic across multiple types. C++ templates are incredibly flexible with partial specialization and fold expressions, extended with constexpr for compile-time logic. The downside is the error messages—the ad hoc nature of templates means the errors also lack structure.
On the other hand, Rust's generics are based on traits (similar to interfaces), allowing for guarded generics with good error messages. However, Rust's compile-time logic and const-generics story is still underdeveloped compared to C++.
One place we use compile-time generics is with version structs. A lot of code at Databento, including in the feed handler, has to support multiple versions of structs as our normalization evolves and when working with exchange protocols that change over time. Usually new versions add one or more fields while keeping the existing ones.

Here's how we handle this in both languages:
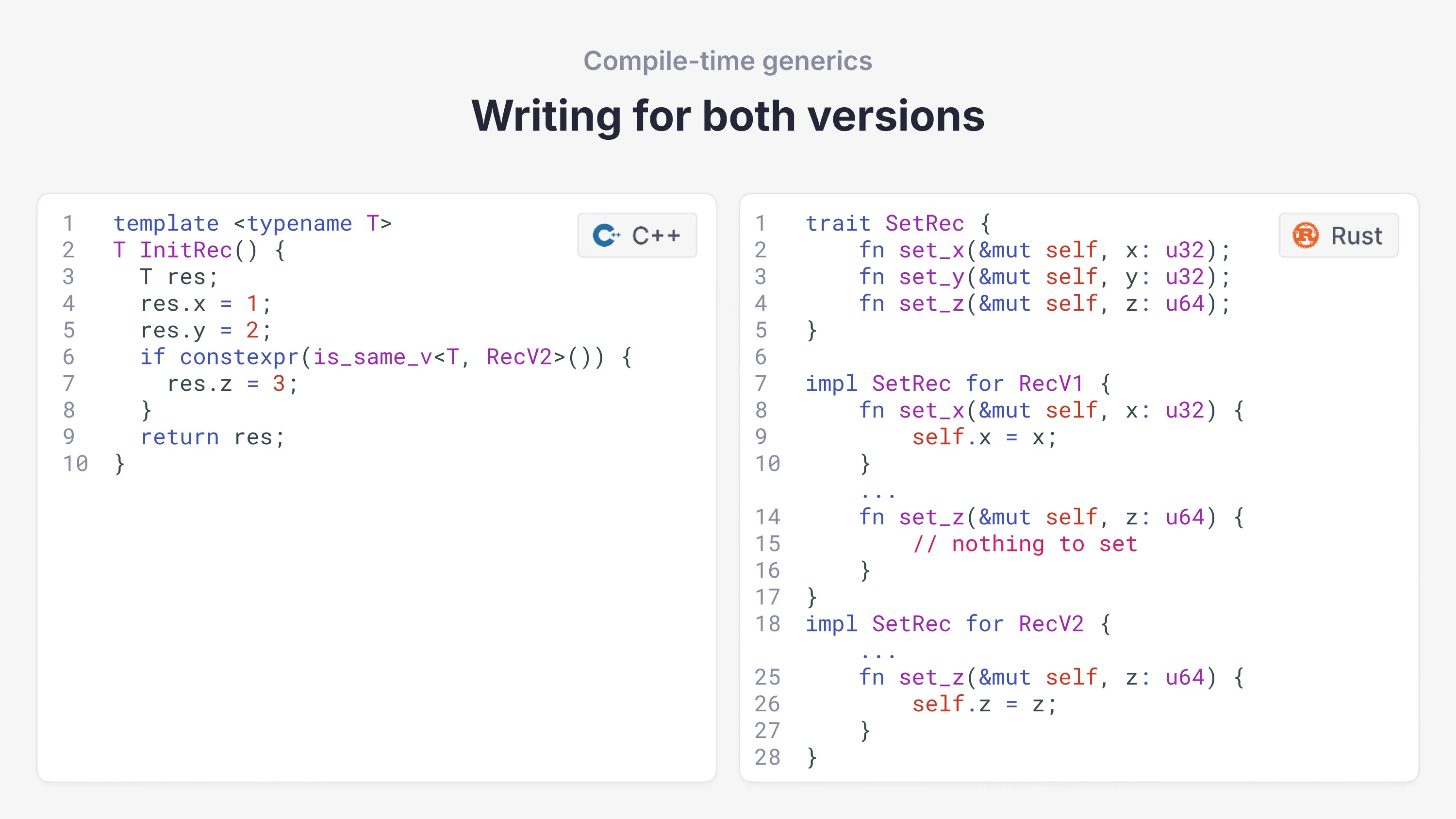
In C++, we don't need to define an interface—templates are ad hoc. We can handle the new field inline with the readable is_same_v check. The interface is implicit, which is fine for simple structures and is fairly readable.
In Rust, this requires defining a trait with a lot of verbose scaffolding. With a couple fields and two versions it's manageable, but with tens of fields and multiple versions, you get an explosion of repetitive boilerplate. We've used macros and code generation to cut down on this, but you're essentially recreating bespoke templates, which is already baked into C++.
These frustrations with Rust led us to choose C++ for the feed handler rewrite, specifically C++23. However, we're far from ruling out Rust in the future. New components and applications will be evaluated on a case-by-case basis, as we believe Rust and C++ have their own niches.
Beyond the technical frustrations, C++ offered several advantages:
- Code reuse from our existing implementation, speeding up the rewrite
- More control over how resources are shared and used
- Flexibility - Templates offer many different patterns for code deduplication
- Team expertise - While everyone has developed in Rust, we have many more years of collective C++ experience
This familiarity meant everyone could be productive immediately with the new feed handler.
C++ continues to excel when maximum control is required. Its more lenient compiler simply doesn't get in the way. This is a benefit in areas with well-established patterns and performance concerns that might not translate well to Rust's ownership model.
While safety in C++ isn't on Rust's level, it's come a long way with sanitizers and tools like clang-tidy that catch more memory and threading issues than in the past.
When dealing with an existing C/C++ codebase, continuing with C++ allows code reuse and reduces build and onboarding complexity.
The Rust vs C++ debate is far from static as both languages continue to evolve. C++26 adds compile-time reflection, allowing programs to examine the structure of types at compile time, which will enable another form of code de-duplication.
Rust also continues to develop. Most notably for the issues we encountered, there's ongoing work on a new and improved borrow checker named Polonius that's more lenient than the current one. It allows more safe borrowing patterns that today are rejected by the borrow checker. However, in our testing, the current implementation did not solve either lifetime issue shown here.
This wasn't a decision driven by performance benchmarks—we didn't write the feed handler in both languages to compare them. The examples shown here were pulled from real issues we've encountered with other Rust applications. This came down more to preference and our belief that C++ was more battle-tested for this specific use case.
We first started adding Rust in isolated areas, kind of as an experiment, and it went very well. Some of the areas where we've used it, like serialization and async networking, are much easier to do in Rust. There are async libraries in C++, but there isn't the same language support, so it's much harder to do and harder to understand.
The takeaway isn't that one language is superior. It's that both Rust and C++ have their place in a modern fintech stack. Rust's safety guarantees and modern tooling make it excellent for many applications. But when you need maximum control over memory layout and resource sharing, when you have established patterns that don't map cleanly to Rust's ownership model, or when you have significant existing C++ code and expertise, C++ remains a compelling choice.
We'll continue using both languages at Databento, choosing the best tool for each job. And as both languages evolve, with C++ adding better safety features and Rust relaxing some restrictions through projects like Polonius, the landscape will continue to shift. The key is making pragmatic decisions based on your specific requirements rather than following language trends.
This post is adapted from a talk presented at Databento’s Chicago Quant Meetup in October 2025.