An introduction to matching engines
This is a guide to all you need to know about matching engines. The content is intended for an algorithmic or quantitative trading audience with an entry-level understanding of exchange infrastructure.
Most of you have used or heard of this term, but probably envision a monolithic block when asked to draw a diagram to describe a matching engine.
A matching engine is usually a collection of servers inside a secure cage. The typical matching engine may compose of hundreds of servers, with many network switches and load balancers between them.
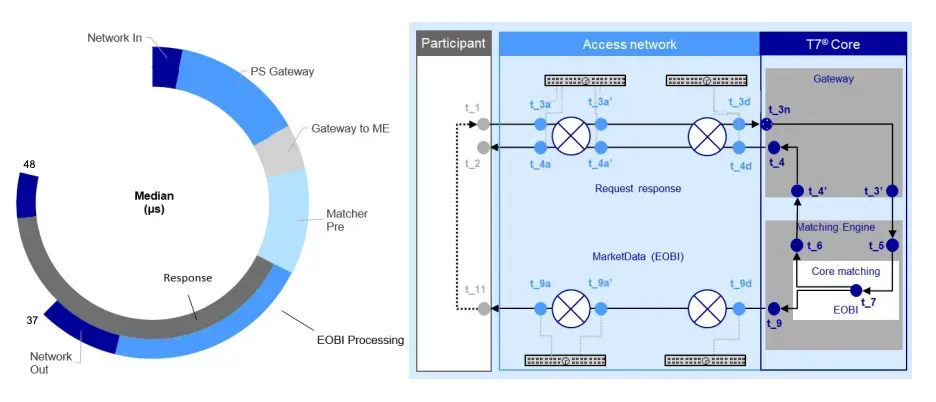
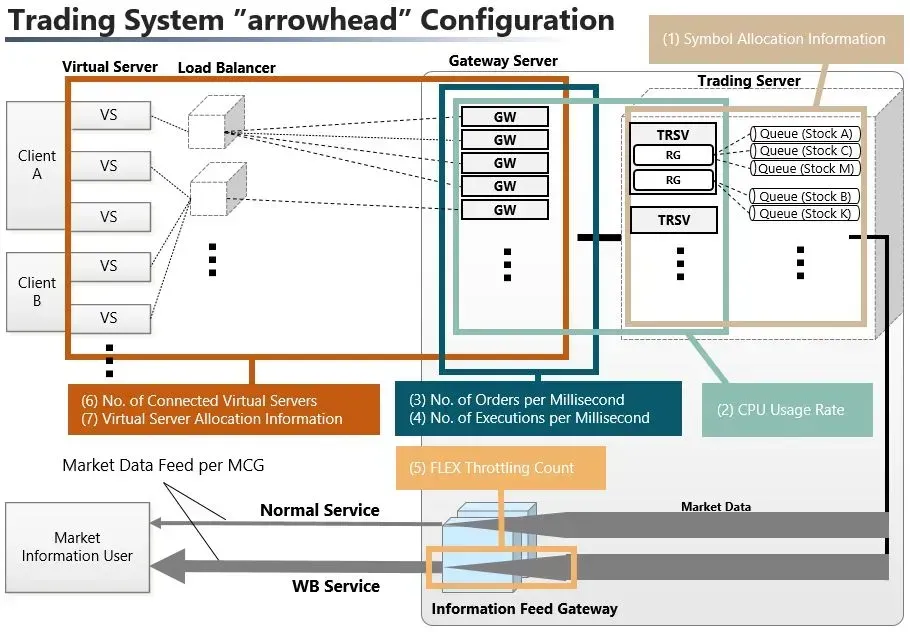
It’s useful to know some terminology to describe a matching engine:
- Primary colocation. The site with the lowest latency that you can connect to the matching engine at. This is usually the data center or facility where the matching engine is housed, however some trading venues do not publicly disclose the location (especially in crypto) or do not allow you to obtain access at the location where their matching engine is housed.
- For example, the primary colocation site of CME’s matching engine is CyrusOne’s Aurora I data center.
- Proximity hosting. Any location, other than the primary colocation site, where you can host your servers to obtain a latency advantage by means of proximity to the matching engine. This term is usually inferred as a data center in the same city, metro region, or neighboring city to that of the primary colocation site.
- Depending on how liberal you are with the term, CyrusOne Aurora II, 350 E Cermak, and AWS Chicago could all be considered proximity hosting locations for CME.
- Point of presence (PoP). Any location where you can obtain a direct connection to the trading venue without an intermediary network provider. Often, one or more proximity hosting locations also serve as PoPs. For example, EBS has PoPs in Secaucus NY2/4/5, Slough LD4, and more.
- Many venues assume the convention that the primary colocation site is not strictly considered a “PoP”, so it may be useful to avoid the ambiguity of this term and explicitly name the data center where you’ll be connecting.
- Latency equalization. The practice of ensuring equal latency between customers whose equipment is situated in the same data center but with varying physical distance to the matching engine. This is usually implemented by means of spooling up a large stretch of optical fiber and having a third-party auditor ensure this is properly implemented, so the term fiber equalization is often used interchangeably.
- For example, Cboe’s matching engine is located in Equinix NY5, but they ensure equal fiber length to customers connecting in NY4 and NY6. Hence for practical purposes, you can consider any of NY4, NY5 or NY6 as primary colocation sites unless you want to be specific about installation instructions or you just like to be pedantic, in which case you could call them latency-equalized PoPs.
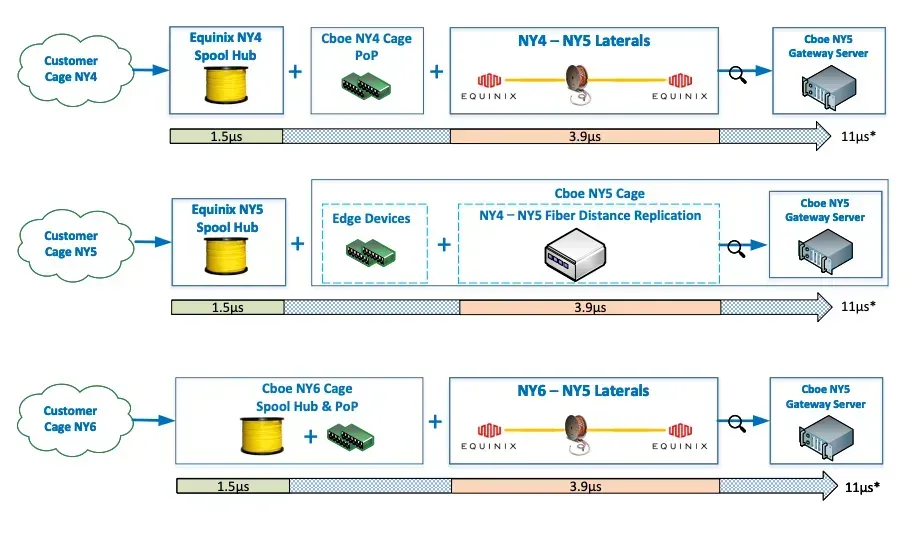
- Smaller exchange operators usually do not exercise latency equalization, because of the additional costs or simply because their trading participants are not very particular about latency advantages. For such venues, third-party colocation providers may keep inventory of their specific handoffs or racks that have a shorter path to the matching engine, and advertise that as a perk or even lease them at a premium.
- Handoff. This is a glorified cross-connect to the matching engine’s extranet. These usually come in 1G, 10G, and 40G flavors. Since the handoff encumbers an access port on the venue-side boundary switch, the term access port is also metonymically used to refer to a handoff, especially when statedon the venue’s fee listings page.
- We say that a handoff is glorified because an ordinary cross-connect within the primary data center is usually around $350 to $550 per month, however trading venues may charge significantly more for the access port that comes with it. For example, a CME 10G handoff (Glink) costs $12,000 per month. One IEX comment letter in 2023 argues for lower fees and stipulates that, in the US equities markets, these fees may be 20x to 40x in excess.
- Boundary switch. A switch where the handoff from the trading venue terminates. Many trading firms and participants reduce their costs by sharing a handoff through a third-party managed services provider (MSP). In such cases, the customer-side boundary switch is usually in the MSP’s rack; low-latency switches, like the Arista 7130, are often used by MSPs.
- Load balancer. Since the matching engine has to handle significant messaging traffic, most matching engine architectures have load balancers that help to distribute the load across servers, e.g. JPX’s matching engine has load balancers between the client and the gateways.
- Wire protocol (or messaging protocol). Most matching engines require a participant to receive data and enter orders according to a messaging protocol. This unlike say, crypto venues that expose higher-level REST and WebSocket APIs. We say that the participant has to implement a client based on the messaging protocol. People also use the terms “wire protocol”, “trading protocol”, “native protocol”, or simply “protocol”.
- Many modern trading protocols are inspired by the FIX protocol or by Nasdaq’s ITCH and OUCH protocols. FIX is a text-based protocol (although binary dialects of FIX like FAST and FIX SBE exist) whereas ITCH and OUCH are binary protocols.
- Direct market access (DMA). This refers to the ability to enter orders to a matching engine directly, e.g. placing orders on its central limit order book without going through intermediaries like a broker or a broker’s order router or gateway, which is in turn often supplied by an independent software vendor (ISV).
- In practice, true DMA or naked access is rarely used and participants are more likely to use the credentials of their clearing firm, broker, or an exchange member firm, or the credit counterparty relationships of their prime broker, to trade on a venue. This is called sponsored access and usually requires a thin layer of supervision on the broker’s part, such as 15(c)3–5 pre-trade risk checks, kill switch access, margin control, etc.
- Matching algorithm. The rules that a matching engine uses to match trades.
- Gateways. The servers in a matching engine that receive order messages or publish market data.
Most matching engines are order-based and have a central limit order book. In turn, most such limit order books are anonymous and match trades in pure first-in-first-out (FIFO) priority. However, a few venues only provide partial anonymity and expose some ways for one to identify the participant behind an order, such as market participant IDs (MPIDs). Pro rata and broker priority are two other popular forms of matching algorithms on venues with central limit order books. Mixed matching algorithms also exist.
Not all matching engines have a central limit order book. Quote-based and request-for-quote (RFQ) markets are popular in FX and fixed income.
From the trader’s perspective, perhaps the part of the matching engine design that has most variation is how the gateways and timestamping at those gateways are implemented.
There are two gateways:
- The order gateway(s), which receives order messages.
- The market data gateway(s), which publishes market data.
In some matching engine architectures, the same server performs both gateway functions.
Depending on the venue, gateways may be assigned to specific sets of symbols. Gateways may also be dedicated one-to-one to a trading participant or shared among different participants. Venues that provide dedicated gateways, e.g. Currenex, usually require you to pay an extra fee as this comes with a latency advantage.
Most trading venues or exchanges don’t operate their own data centers, with some notable exception being ICE with its Basildon facility and its subsidiary NYSE with its Mahwah facility.
Equinix is the most widely-used, third-party operator of data centers where matching engines are housed. Hence if you see three-character codes used to refer to data centers — like NY4, LD4, FR2 — these are usually following Equinix’s naming convention. Other data center operators may also recycle the same codes.
Being familiar with one venue will usually give you insights into another. There’s no one standard design or architecture of a matching engine, but most of them share some similarities — say, knowing Nasdaq’s ITCH spec will familiarize you with Cboe FX’s ITCH dialect, even though one uses UDP while the other uses TCP. Moreover, many venues don’t implement their own matching engine, but instead license from another venue, with popular matching engine implementations being:
- Nasdaq. Used in over 70 markets such as SGX and JPX.
- Deutsche Boerse T7.
You can determine the matching algorithm used for each instrument on Databento’s instrument definitions data:
# Print instrument and matching algorithm on CME
import databento as db
client = db.Historical("YOUR_API_KEY")
data = client.timeseries.get_range(
dataset="GLBX.MDP3",
schema="definition",
symbols="ALL_SYMBOLS",
start="2024-08-20",
end="2024-08-21",
)
df = data.to_df()
print(df[['symbol', 'match_algorithm']].head())raw_symbol match_algorithm
ts_recv
2024-08-20 00:00:00+00:00 WB3Q4 P1290 Q
2024-08-20 00:00:00+00:00 NKWU4 P33200 F
2024-08-20 00:00:00+00:00 LOX4 P250 F
2024-08-20 00:00:00+00:00 OHV4 P24900 F
2024-08-20 00:00:00+00:00 ZN1U4 P1235 QA crucial piece of information for backtesting is a timestamp as close as possible to the handoff. This is used to determine how fast you can react to a market data event.
This is included as ts_recv in Databento’s normalized data.
Many quantitative or algorithmic trading opportunities that may appear in simulation or backtesting are not actionable (we say these cannot be monetized), because the price move that you’re trying to capture happens before you can react to it.
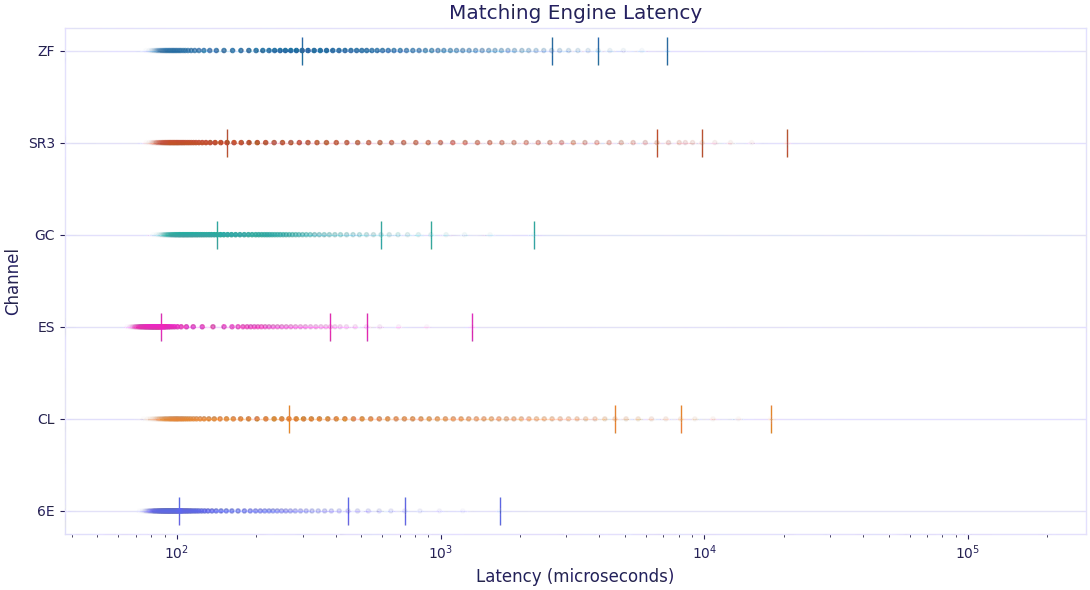
The internal latency of a matching engine is not constant. During periods of high volatility, the latency is usually much larger. Likewise, load and matching engine latency varies with product, as seen here.
You can generate such a plot with Databento’s MBO (L3) data:
import databento as db
import databento_dbn as dbn
SYMBOLS = (
"ES.FUT",
"SR3.FUT",
"6E.FUT",
"ZF.FUT",
"GC.FUT",
"CL.FUT",
)
# First, create a historical client
client = db.Historical(key="YOUR_API_KEY")
mbo = client.timeseries.get_range(
dataset="GLBX.MDP3",
schema="mbo",
symbols=SYMBOLS,
stype_in="parent",
start="2024-01-26T05:00:00-6",
end="2024-01-26T17:00:00-6", # 12 hours of mbo
)
mbo_df = mbo.to_df(pretty_ts=False, map_symbols=False)
# Filter out any records with a bad ts_recv timestamp
mbo_df[mbo_df["flags"] & db.RecordFlags.F_BAD_TS_RECV == 0]
# Check for bad timestamps
if (mbo_df.index == dbn.UNDEF_TIMESTAMP).any():
raise ValueError("Data contains one or more undefined ts_recv timestamps")
if (mbo_df["ts_in_delta"] == dbn.UNDEF_TIMESTAMP).any():
raise ValueError("Data contains one or more undefined ts_in_delta timestamps")
# Calculate latency
mbo_df["latency_matching_us"] = (
mbo_df.index - mbo_df["ts_in_delta"] - mbo_df["ts_event"]
) / 1e3
mbo_df["latency_send_to_recv_us"] = mbo_df["ts_in_delta"] / 1e3
mbo_df = mbo_df[["instrument_id", "latency_matching_us", "latency_send_to_recv_us"]]See the rest of the code here.
Since the matching engine is itself a distributed software application with multiple hot paths, it shouldn’t surprise you that you can gain a latency advantage by having multiple connections or routing to a gateway that’s under least load.
Most sophisticated DMA traders will usually have multiple order sessions and at least round robin their orders across them, if not have a way to evaluate the session that has the lowest latency.
Likewise, it’s possible to gain latency advantage by “warming” the path — much like cache warming for a software application — and keeping a port or session in use with a steady stream of order messages. This is practice is called port warming.
Most trading venues implement their raw direct feeds in the form of two UDP multicast feeds. UDP is a lossy protocol, so this provides redundancy in case packets are dropped in the path. The two feeds are usually referred to as the A and B feeds.
Since the A and B feeds have to be published by separate subcomponents of the matching engine, their latencies will usually differ.
By how much? See for example the estimated latency between the two feeds (positive means A is ahead) extracted from Databento’s PCAPs of the Nasdaq’s TotalView-ITCH feed on June 17, 2024:
time,min_ns,mean_ns,max_ns,stddev_ns
"2024-06-17 08:01:00 UTC",549567,566902,569354,259
"2024-06-17 08:02:00 UTC",556538,566909,578539,276
"2024-06-17 08:03:00 UTC",559440,566913,569817,245
"2024-06-17 08:04:00 UTC",564651,566930,572000,248
"2024-06-17 08:05:00 UTC",564187,566900,569517,248
"2024-06-17 08:06:00 UTC",562756,566904,572166,243
"2024-06-17 08:07:00 UTC",563904,566898,573938,247
"2024-06-17 08:08:00 UTC",564668,566900,570601,245
"2024-06-17 08:09:00 UTC",564258,566887,569631,256
"2024-06-17 08:10:00 UTC",564822,566907,570622,241
"2024-06-17 08:11:00 UTC",564872,566877,571475,235
"2024-06-17 08:12:00 UTC",563862,566896,569619,244
"2024-06-17 08:13:00 UTC",563798,566908,569440,234
"2024-06-17 08:14:00 UTC",562621,566890,570404,240
"2024-06-17 08:15:00 UTC",563555,566887,569224,236
"2024-06-17 08:16:00 UTC",557120,566923,571228,244
"2024-06-17 08:17:00 UTC",564759,566884,570757,236
"2024-06-17 08:18:00 UTC",560969,566901,569083,237
"2024-06-17 08:19:00 UTC",563209,566874,569752,234
"2024-06-17 08:20:00 UTC",564987,566962,569317,231You can see that the B-side is consistently more than 500 µs behind the A-side. There’s no rule that the A-side must be faster than the B-side; the B-side may be consistently ahead of the A-side depending on gateway or venue, and this may change over time.
For those who’re familiar with typical time scales in trading, 500 µs is very significant. It can cost $10⁵~ in development costs to squeeze out tens of nanoseconds of marginal latency improvement — all that’s pointless if you’re just listening to the wrong feed side.
If you’re familiar with Databento, you’ll also know that we usually recommend our users to design their application logic, e.g. signals and execution, to be robust to missing data and packets. A common motivation for this is that sophisticated traders will usually listen to the faster feed side only and accept that they may lose packets.
Many traders hold exchange-embedded timestamps to a high standard, but in fact exchange timestamps can often be much worse than your own!
- Most matching engines do not use accurate time synchronization techniques like PPS, PTP or White Rabbit.
- Some venues only provide millisecond resolution timestamps.
- Many venues don’t distinguish between market data publication timestamp and matching timestamp even though the two may differ by milliseconds or more.
- Many venues do not guarantee monotonicity in their timestamps.
The ts_recv timestamp in Databento’s normalized data uses PTP time synchronization to mitigate these issues.
We’ve shown some use cases of Databento to study matching engine behavior above. If you’d like to know more about our data solutions, here’s some additional background knowledge.
Market data in raw packet capture format includes every data message sent from the matching engine, preserving other layers of encapsulation like packet headers, the original sequence of packets, and more. It also includes the capture timestamp in addition to venue-embedded timestamps.
Here’s an example of Databento’s CME PCAPs decoded to text:
Binary Packet Header:
Message Sequence Number: 284697
Sending Time: 1662336000000443945
Message:
Message Size: 96
Message Header:
Block Length: 11
Template Id: Md Incremental Refresh Trade Summary 48 (48)
Schema Id: 1
Version: 9
Md Incremental Refresh Trade Summary:
Transact Time: 1662336000000029437
Match Event Indicator: Last Trade Msg
End Of Event: Yes (1)
Reserved: Yes (1)
Recovery Msg: Yes (1)
Last Implied Msg: Yes (1)
Last Stats Msg: Yes (1)
Last Quote Msg: Yes (1)
Last Volume Msg: Yes (1)
Last Trade Msg: Yes (1)
Padding 2: 00 00
M D Incremental Refresh Trade Summary 48 Groups:
Group Size:
Block Length: 32
Num In Group: 1
M D Incremental Refresh Trade Summary 48 Group:
Md Entry Px: 110.8125
Md Entry Size: 1
Security Id: 406280
Rpt Seq: 47780
Number Of Orders: 2
Aggressor Side: Buy (1)
Md Update Action: New (0)
Md Trade Entry Id: 76637
Padding 2: 00 00
M D Incremental Refresh Trade Summary 48 Order Groups:
Group Size 8 Byte:
Block Length: 16
Padding 5: 00 00 00 00 00
Num In Group: 2
M D Incremental Refresh Trade Summary 48 Order Group:
Order Id: 8410916265517
Last Qty: 1
Padding 4: 00 00 00 00
M D Incremental Refresh Trade Summary 48 Order Group:
Order Id: 8410916370744
Last Qty: 1
Padding 4: 00 00 00 00Lossless packet captures are like “ground truth”, a higher standard than even standard tick data, normalized “L3” data, or raw binary data bought directly from the exchange.
Aside from Databento, there are only 4 other vendors that provide market data PCAPs. These form a crucial backbone of the financial data ecosystem.
- Databento
- LSEG
- Pico
- ICE
- Quincy Data
A variety of vendors provide PCAP replay and decoding tools, e.g. OnixS, Exegy. Databento makes it even easier to get data with PCAP-level granularity by providing normalized MBO (L3) data that is enriched with up to 4 timestamps.
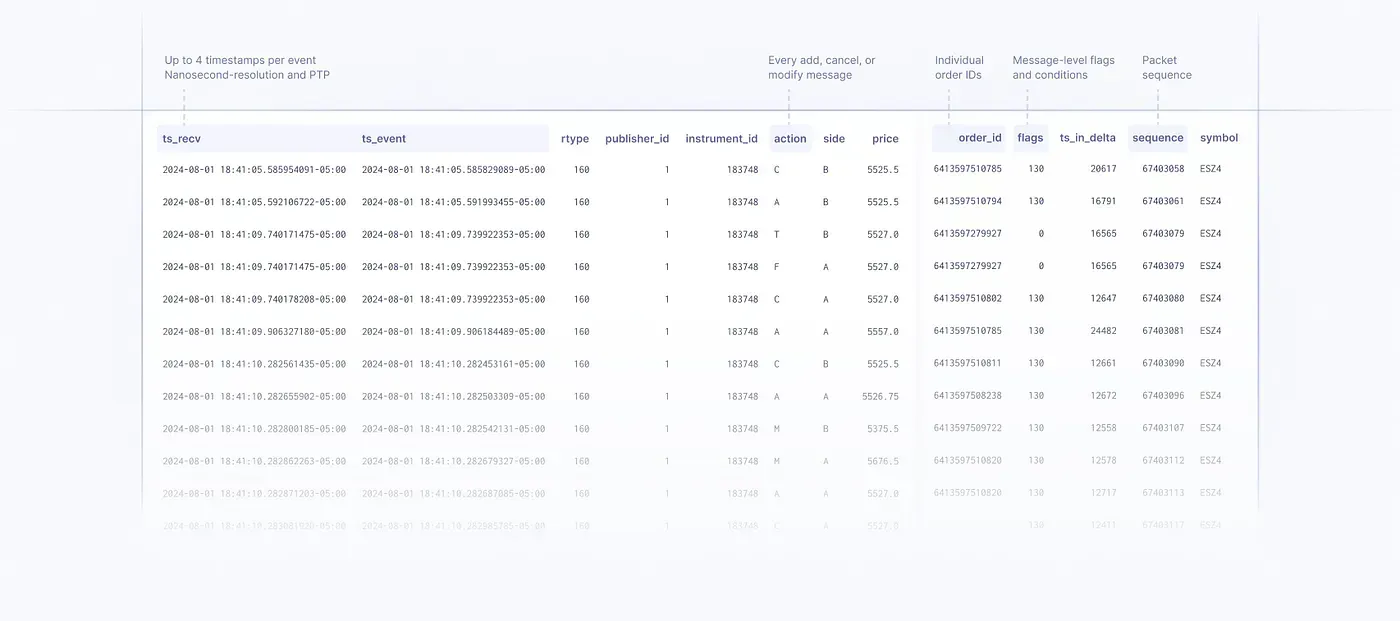
If you’re backtesting with market data that has only one type of timestamp, you’re probably missing out on free information about the matching engine that can be used to your advantage.
- Johnson, B. (2010) Algorithmic Trading and DMA: An introduction to direct access trading strategies. For more about DMA.
- Matching Algorithm Overview, CME Group. For some common types of matching algorithms, as found on CME.
- Insight into Trading System Dynamics, Deutsche Boerse presentation, July 2024. For details of the T7 matching engine architecture.
- TMX Order Types. How broker preferencing (price-broker-time priority) works on TSX, TSXV, TSXA.
- Island ECN source code. The original Island matching engine developed by Josh Levine that inspired many others to come.
Databento is a simpler, faster way to get market data. We’re an official distributor of real-time and historical data for over 40 venues, and provide APIs and other solutions for accessing market data.
Interested in more articles on practical market microstructure like this? Check out Databento’s blog.