How we serve real-time tick data of the entire US options market over the internet—on a single server
Our US equity options feed effortlessly delivers real-time tick data from all 17 exchanges, timestamped to the nanosecond—streaming over 1.4 million tickers online. Just pass it symbols='ALL_SYMBOLS', and that's it. No expensive colocation, cross-connect, or private extranet connection is needed.
With efficient load balancing for redundancy and horizontal scaling, we serve multiple clients using a single server, bypassing complex setups like autoscaling and distributed streaming platforms to avoid sharing or buffering the feed.
Before delving into our approach at Databento, let's explore the challenges posed by high-bandwidth data like OPRA.
OPRA bandwidth and line-rate processing play a crucial role in understanding the complexities of handling US equity options data.
Before we delve further, if you're unfamiliar with US equity options, here's a helpful chart to provide context and perspective.
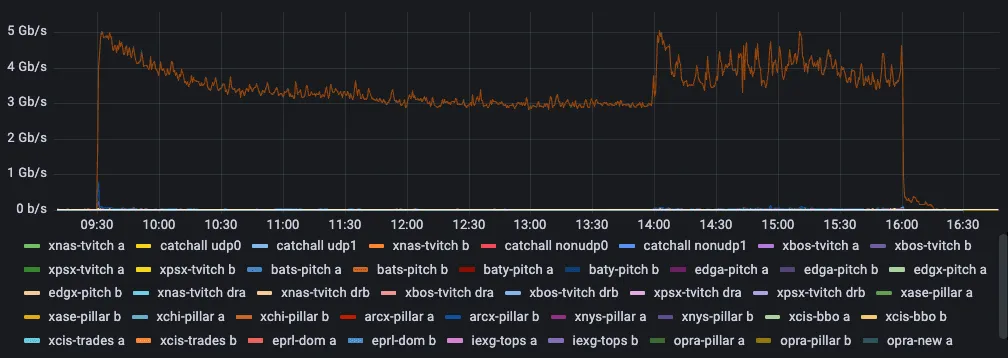
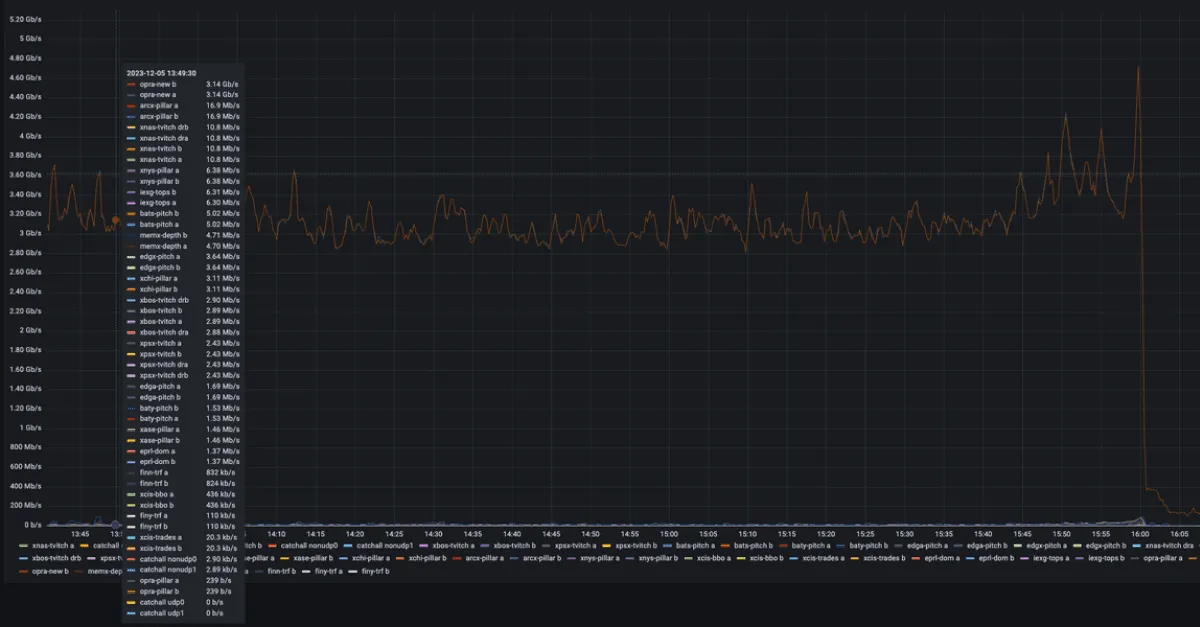
We capture direct proprietary feeds to access comprehensive depth and order book data from nearly all US stock exchanges and the three TRFs. While each presents challenges with microbursts, OPRA stands out as the most demanding when plotted side-by-side.
A single day of OPRA PCAPs amounts to about 7 TB compressed—after erasure coding and parity, filling one large hard disk drive daily. OPRA estimates a bandwidth requirement of 37.3 Gbps to support the feed, or 53 Gbps when combined with the CTA SIP.
Perhaps what's the most impressive technical feat is the ability for users to tailor specific combinations of symbols and multiplex subscriptions to combinations of message types. For example, one user might be monitoring tick-by-tick quotes for VIX and SPY options chains, while another user might be aggregating data for all symbols at 1-second and 1-minute intervals.
import databento as db
live = db.Live()
live.subscribe(
dataset="OPRA.PILLAR",
schema="trades",
stype_in="parent",
symbols=["TSLA.OPT", "SPY.OPT"], # symbol selection
)
for record in live:
print(record)Our server meets the dual demands of both a simple firehose and a more stateful capability to manage customized subscriptions and filter symbols. Other vendors bypass this technical challenge by picking one of the two strategies: a firehose often requires less processing and fewer queues, while limited symbol subscriptions reduce bandwidth requirements.
1. Keep things simple and choose proven technology. Coming from the high-frequency market-making world, our team recognized the need to acquaint ourselves with modern tech stacks and distributed streaming frameworks. In HFT and many financial trading systems within the colo, distributed processing is often viewed as counterproductive.
Upon surveying the landscape, we noticed many of the existing vendors were using Kubernetes, Kafka, WebSocket, or various databases like kdb and Vertica, requiring extensive server infrastructure. We did our napkin math and thought all that was unnecessary.
Instead, we quickly mocked up a design based on bare metal servers, simple multicast, binary flat files, lock-free queues, and BSD sockets over a day.
Simple architectures excel here, reducing traversal down the I/O hierarchy, which is usually the most expensive part of any data-intensive application. Keeping processes on a single thread or utilizing interprocess communication on one processor is much cheaper than involving networked calls across multiple servers.
We're not alone. There are many great stories about scaling with simple architectures:
- "Choose boring technology" was first coined by Dan McKinley, who overlapped with our senior systems engineer, Trey Palmer, at Mailchimp.
- StackExchange's 2016 architecture write-up is a great example of how monolithic architectures can serve the performance requirements of a hyperscale company.
- The founding story of Redline Trading Solutions states that Matt Sexton and his team redid Goldman Sachs's US equity options infrastructure, which at the time needed a whole rack of servers. In the end, they had shrunk it down to four servers.
- Twitch's infrastructure team shares many wisdoms on how to scale bare-metal environments.
2. Flat files and embedded databases are amazing. Our real-time API boasts an additional feature: it allows replay of intraday historical data from any start time in the session in an event-driven manner, as if it were real-time. Then, it seamlessly joins the actual real-time subscription after the client catches up.
import databento as db
live = db.Live()
live.subscribe(
dataset="OPRA.PILLAR",
schema="trades",
symbols="ALL_SYMBOLS",
start="2023-08-31T13:30", # intraday replay
)
live.start()This feature is useful in many trading scenarios. For example, if you started your application late and needed to burn in signals with a minimum lookback window or if your application crashed and needed to restart. Having the historical portion emulate the real-time feed also means you can use the same code and the same set of callbacks to handle both, avoiding costly implementation mistakes.
Despite this common use case, not many vendors or trading venues offer this. For example, with Coinbase's API, to get the initial book state, you'd have to subscribe to the real-time WebSocket feed, and while buffering up the real-time messages, dispatch an initial book snapshot request over the REST API, then stitch the two parts together by arbitrating sequence numbers.
Implementing this feature on Databento's server introduces complexity, as the server must buffer the real-time feed while the client catches up, leaving room for denial attacks.
We implemented this quite simply, using plain flat files with an indexing structure, zero-copy transfer and serialization techniques, and a C driver. The whole library, supporting utilities, and data structures are less than 2,000 lines in pure C.
A more fancy term for this is a "serverless database," as coined by Man Group's team for Arctic, or an "embedded database," as Google's LevelDB and Meta's RocksDB are described.
Many notable projects have achieved performance gains by adopting embedded databases. For example, Ceph saw significantly improved performance after an architectural change to their BlueStore backend based on RocksDB. RocksDB is the default state store in Kafka Streams and the entry index database for bookies in Pulsar. One of the major departures from Arctic's design from its previous iteration is the switch from a MongoDB backend to its new serverless design.
3. Know when to throw more (expensive) hardware at the problem. Developer time is costly. Investing in a $10k FPGA offload NIC, a $20k switch, and an additional server may seem expensive, but it pales in comparison to the costs incurred by a month of wasted developer time.
The earliest design of our options stack involved sharding the OPRA lines across several servers and then muxing the smaller, normalized output on a separate layer of distribution servers. This envisioned a hierarchical architecture that would allow us to use cheaper NICs and scale linearly and independently for an increase in incoming feed message rate vs. an increase in client demand, which would theoretically reduce server cost in the long run. This architecture is not novel; we know at least one major retail brokerage that adopts this.
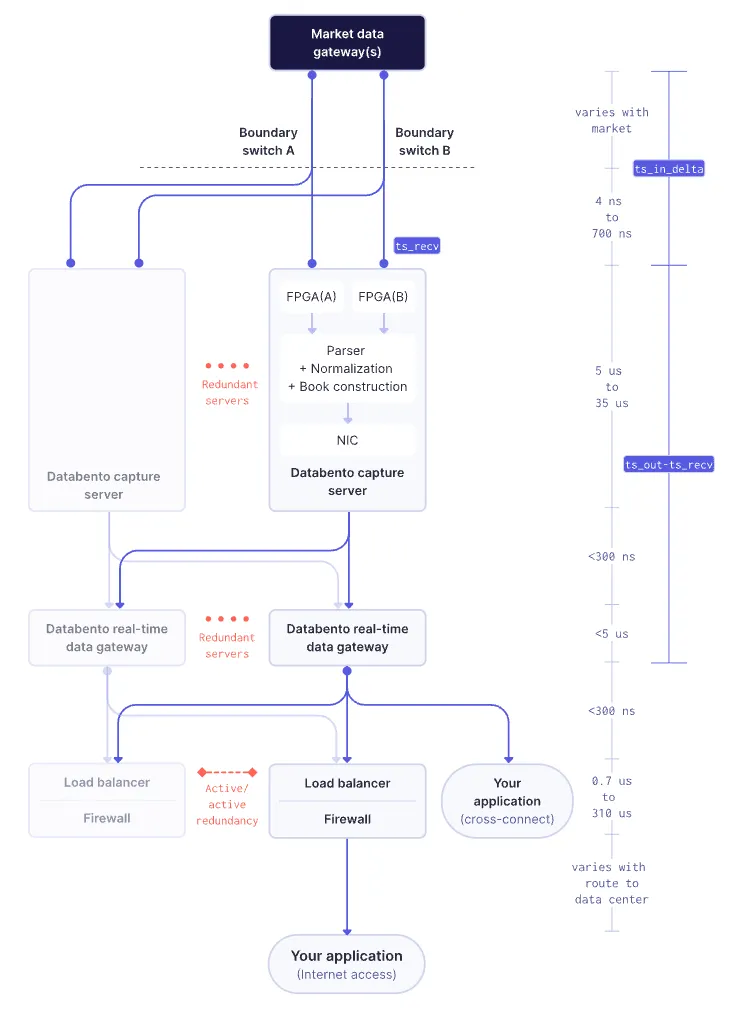
Ultimately, we ended up with a shared-nothing, distributed monolith design that only needed a single beefier server, with a 100G Napatech SmartNIC, to process the entire feed and fan out customer traffic. Scaling and redundancy is achieved by adding more servers and simple load balancing (direct server return) over them.
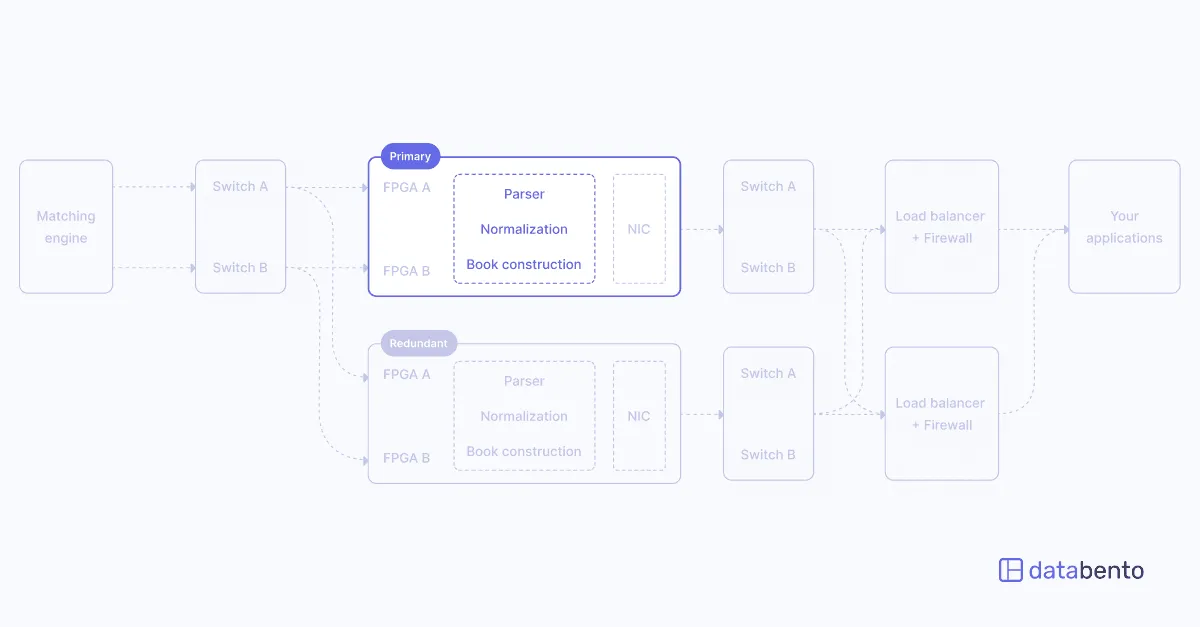
4. Kernel bypass networking is cheap. One of the first "wow" moments of our early careers in electronic trading was compiling Mellanox's userspace networking library, then called Voltaire Messaging Accelerator. The ordeal took less than 30 minutes and we saw a nearly five-fold decrease in UDP round-trip one latency and a significant improvement in throughput.
Two parts of our OPRA real-time architecture employ kernel bypass: the live gateway application and the load balancer.
These days, you can pick up a Mellanox ConnectX-4 NIC for as little as $70 on eBay and a brand new Xilinx (Solarflare) NIC for just over $1k. You should know about kernel bypass if you're providing any hyperscale or performance-sensitive web service. There's a good introduction on Cloudflare's blog by Marek Majowski.
5. Use a binary format and efficient encoding/decoding. Binary encoding is almost a must for anything involving tick data or full order book data. It's strange to put in all the effort to support a massive stack of Apache data frameworks, bare metal Kubernetes, IaC tools, and microservices and then lose a significant amount of time in JSON encoding and decoding.
We wrote our own binary format, Databento Binary Encoding (DBN), with a fixed set of struct definitions that enforce how we normalize market data. Among many of the optimizations found in DBN is that we squeeze every MBO ("Level 3") message into a single cache line.
6. Build it yourself. Because of the storage and bandwidth requirements, it's important to note that there are few official, real-time OPRA distributors like us.
When you whittle down the API distributors that can deliver over the internet or public cloud, there are only a handful. Of the remaining ones, several are white-labeling and redistributing another vendor's feed or using other ISVs' feed handlers, a common practice in the market data space. (Some vendors whose feeds and parsers we've seen get white-labeled include Exegy, dxFeed, and QUODD.) Instead, we write our own feed parsers and book builders.
It's no unique insight that building it yourself allows you to optimize further. However, one important benefit specific to market data is that a lot of data integrity is lost in the way that data is normalized. As an aside, a good normalization format will usually allow you to "compress" the raw multicast feed into a more lightweight feed, and discard unnecessary fields or bloat.
Writing a feed parser can seem daunting to a newcomer in this space, but at a market-making firm, you usually reach a point where each engineer is churning out a new parser every two weeks.
7. Network. Delivering order book data over internet requires a significant investment in your network. There's no way around this but to aggregate a lot of transit bandwidth from several tier 1 providers—something we've done with the help of our partners such as Point5, Netris, NVIDIA Networking, and TOWARDEX.
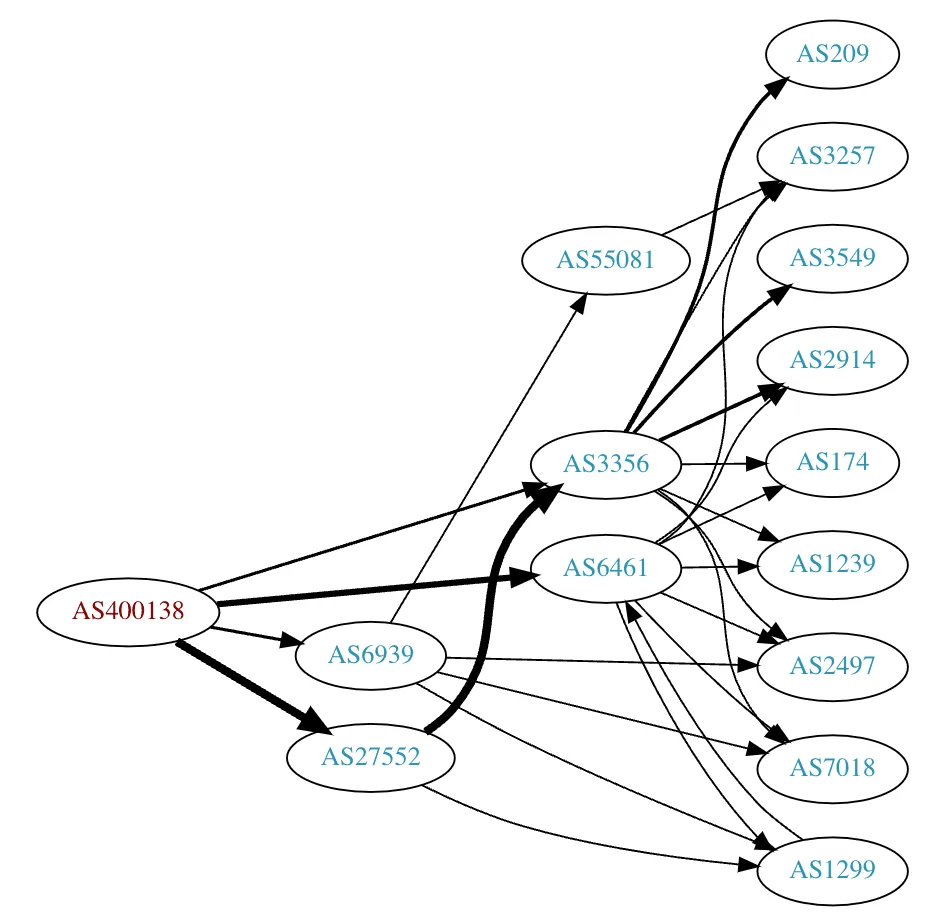
If you're connecting over the internet or cloud, one metric that correlates strongly with the quality of your financial data or connectivity provider can be extracted from looking at their ASN and seeing the observed AS paths and the quality of their peers. This gives you a sense of how extensively they've built up their network.
Some caveats about this methodology:
- It strictly only gauges cloud and internet-based distribution capability.
- It may be imprecise as some vendors have multiple ASNs with overlapping peers. Vendors could also rank better simply because they have more data centers, but their service may be worse if the feed is only served out of one data center with no route diversity.
- Many other qualities go into a feed, such as data integrity, ease of API integration, latency, and uptime, which can't be measured this way.
- The list would be entirely different for direct connectivity solutions and ISV gateways. Some of the firms listed, like Activ and Exegy, as well as others not on this list, like Onix and Celoxica, would rank high. Databento doesn't sell a feed appliance or gateway software and wouldn't be included in such rankings.
- There are diminishing returns to AS connectedness, so the ranking order between the top 5 would be less meaningful.
With that said, here's a loose list of what we consider to be the top 15 financial data providers for a cloud or internet-based solution according to this methodology:
- Bloomberg
- Trading Technologies
- ICE Data Services
- Refinitiv
- IRESS/QuantHouse
- Broadridge
- Databento
- Devexperts
- Activ Financial
- FactSet
- CQG
- Exegy
- Barchart
- Spiderrock
- Quotemedia
In addition, having dedicated interconnects to major cloud on-ramps and proximity hosting locations allows us to provide stable feeds and distribute our traffic further. Currently, we support dedicated interconnects to AWS, Google, and Azure at the Equinix CH1 and NY5 on-ramps, as well as major colocation sites in Europe like Equinix LD4 and FR2.
8. Invest in people and a strong engineering culture. This is self-explanatory. It's fitting to add parting words from our CEO and CTO:
"All this wouldn't have been possible without the work of the awesome engineers on our core and systems teams. These folks took breaks from lucrative careers in high-frequency trading and large tech firms to join an unheard startup based in Salt Lake City. They'll have our eternal respect."