Behind the scenes: How we built the world’s fastest cloud-compatible ticker plant
When we kicked off the design for Databento’s real-time feed in 2023, there were only a few options for real-time market data on the market that we considered competitive.
Most of them require you to deploy your own colocated server and merely offer a software license to run their ticker plant either interprocess or intraprocess. This setup usually runs at least $8,000 per month once you add up vendor fees, exchange access fees, hosting fees, and more.
The few that did provide a normalized feed that can be accessed over internet were usually limited on symbol subscriptions, had poor performance guarantees, or sidestepped these issues with a very rigid data model limited perhaps only to top of book (L1) or limited-depth (L2) data.
So, we sought out to build a feed that would solve all of those problems:
- Fast. Needs to be fast enough that it could achieve performance in public cloud that was previously only achievable with colocation, helping a wide class of users mitigate significant costs.
- All-symbol firehose. Needs to be able to deliver trades from every ticker on a large feed like OPRA (about 1.4 million symbols) or CME (about 700k symbols).
- Open source. No need to run a third-party binary or install a compiled library.
- Flexible. The user must be able to pick from multiple data formats and symbols, and mux them together.
- Full order book. The solution needed to keep up with the throughput of full order book (also called MBO or L3) data over internet.
- Same API and message structures as historical data. Since we already offered historical data, we wanted our users to have parity so it would be easy for them to roll out an application developed on our historical data into real-time.
- Accurate. The data needed to be comparable or better than gold-standard data sold directly by trading venues or the 2 to 4 leading data providers that serve most institutions. It has to be lossless, easy to correlate to packet captures, and synced to GPS time source.
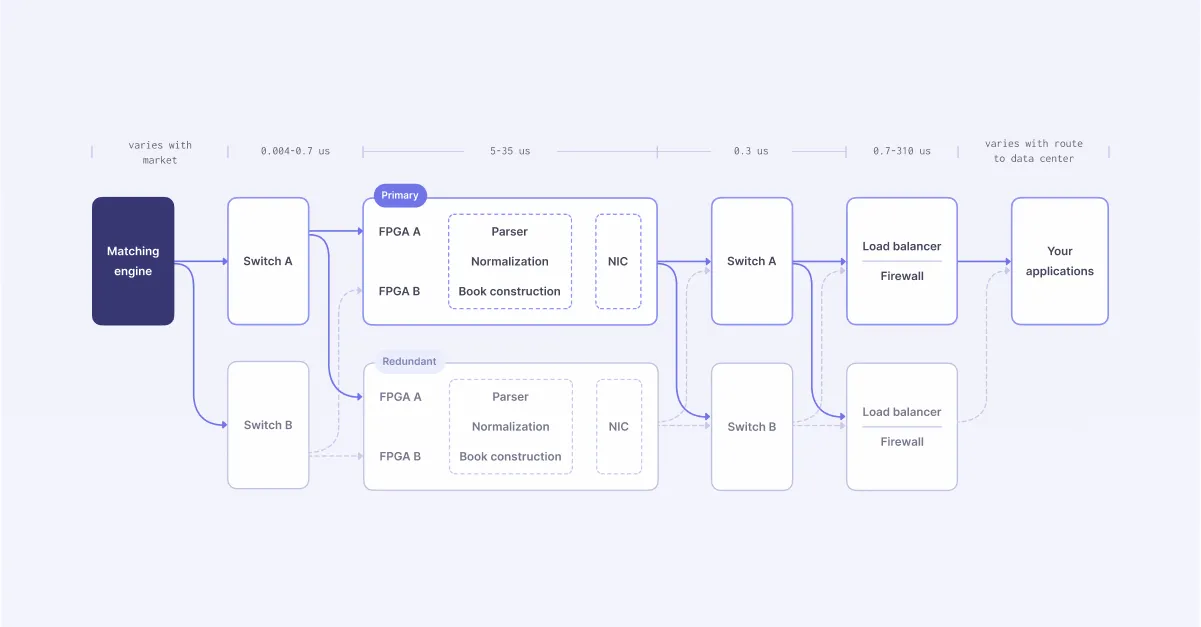
The following diagram summarizes the key design principles of the architecture that we came up with.
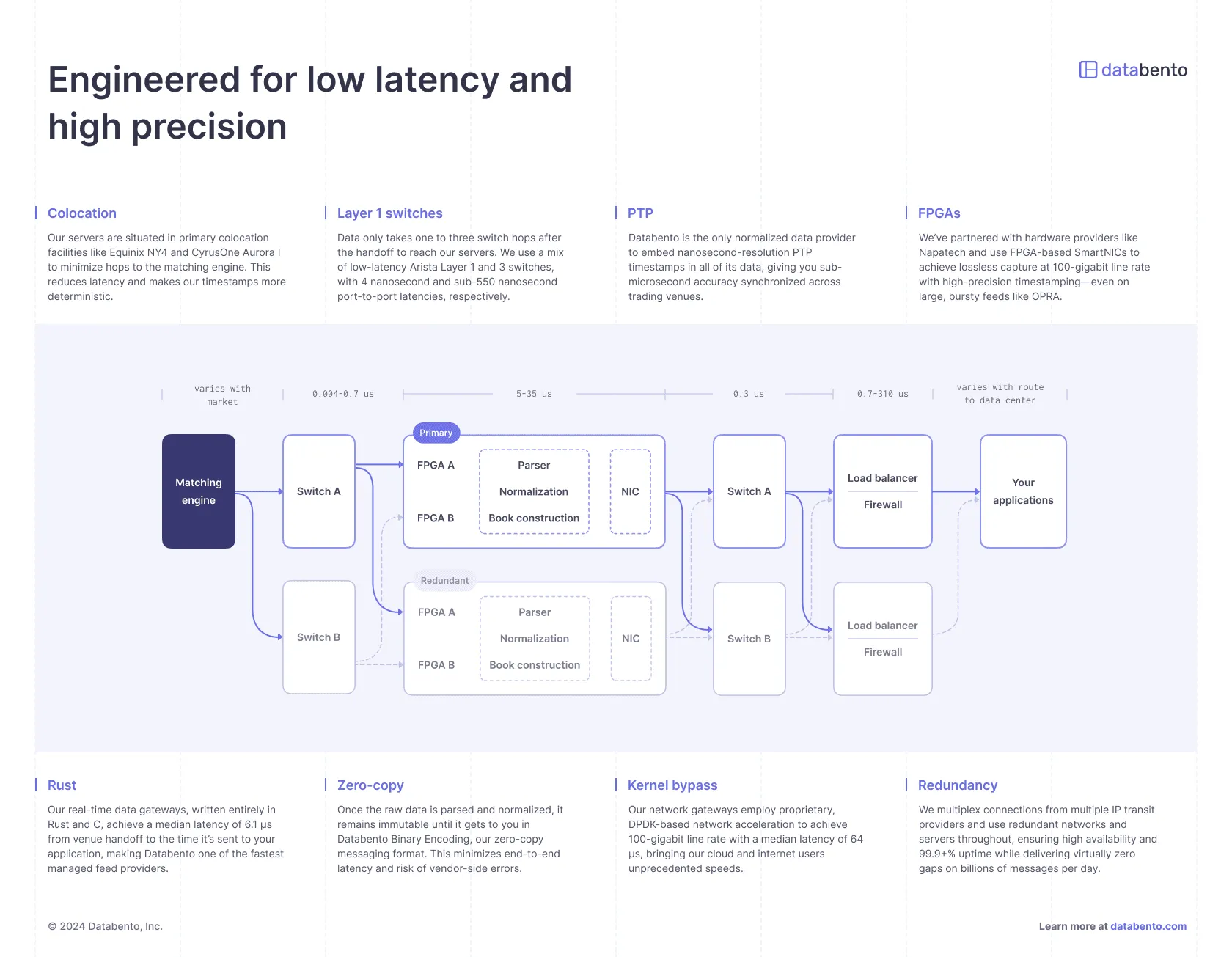
Our servers are situated in primary colocation facilities like Equinix NY4 and CyrusOne Aurora I to minimize hops to the matching engine. This reduces latency and makes our timestamps more deterministic.
Data only takes one to three switch hops after the handoff to reach our servers. We use a mix of low-latency Arista Layer 1 and 3 switches, with 4 nanosecond and sub-550 nanosecond port-to-port latencies respectively.
Databento is the only normalized data provider to embed nanosecond-resolution PTP timestamps in all of its data, giving you sub-microsecond accuracy synchronized across trading venues.
We’ve partnered with hardware providers like Napatech and use FPGA-based SmartNICs to achieve lossless capture at 100-gigabit line rate with high-precision timestamping—even on large, bursty feeds like OPRA.
Our real-time gateways, written entirely in Rust and C, achieve a median latency of 6.1 µs from venue handoff to the time it’s sent to your application, making Databento one of the fastest managed feed providers.
Once the raw data is parsed and normalized, it remains immutable until it gets to you in Databento Binary Encoding, our zero-copy messaging format. This minimizes end-to-end latency and risk of vendor-side errors.
Our network gateways employ proprietary, DPDK-based network acceleration to achieve 100-gigabit line rate with a median latency of 64 µs, bringing our cloud and internet users unprecedented speeds.
We multiplex connections from multiple IP transit providers and use redundant networks and servers throughout, ensuring high availability and 99.9+% uptime while delivering virtually zero gaps on billions of messages per day.
The design is very simple and has few moving parts and external dependencies — the first version of our application that performs parsing, normalization and book construction compiled in less than 1 second!
We rely on simple strategies like multicast, IPC over lock-free queues, direct server return, and an internally-crafted zero-copy messaging format called Databento Binary Encoding — the Rust reference implementation of which has become one of the most actively-downloaded crates. Everything runs on bare metal and we use Puppet for configuration and Ansible for deployment.
There’s no Kubernetes, Kafka, fancy ingress controller, persistent message broker, protocol buffers, Apache Beam/Flink—we don’t like stitching together large open source projects with many external dependencies.
This has held up through 2024 where our revenues grew 958% Y/Y and our API traffic grew by 2 orders of magnitude. But we expect the next generation of the design to support channel-by-channel sharding and more intelligent load balancing.
One challenge with the simplicity and speed is that earlier iterations of our service had poorer uptime or edge cases in deployment that could break production—the sort of issues that sometimes come with nascent, inhouse technologies. This has gotten significantly better, and we’re transparent about uptime on our public status page.