









Although CL and BRN are liquid futures contracts, there's the possibility that both sides don't print in a given minute interval. A more complete implementation should resample during every minute of the trading session.
 Pairs trading based on cointegration
Pairs trading based on cointegration
Pairs trading is a form of statistical arbitrage that takes advantage of the co-movement in prices of two instruments. It seeks to profit from the convergence the two prices.
The simplest variation of this strategy involves going long and short simultaneously on a pair of cointegrated instruments. But more generally, you can construct a spread from any linear combination of the two instruments with the approach in this tutorial—even going long simultaneously on two instruments.
Setup and dependencies
We'll make use of the following external libraries:
- matplotlib for plotting.
- numpy for data manipulation.
- pandas for data manipulation.
- scikit-learn to fit the linear regression between the two price series.
- statsmodels for the Engle-Granger two-step cointegration test.
import databento as db
import matplotlib.pyplot as plt
import numpy
import pandas as pd
from statsmodels.tsa.stattools import coint
from sklearn.linear_model import LinearRegression
CME WTI (CL) vs. ICE Brent crude oil (BRN)
We'll demonstrate the pairs trading strategy on the two most liquid crude oil products traded on CME and ICE, the WTI crude oil futures (CL) and Brent crude oil futures (BRN) contracts respectively.
This also showcases the value of Databento's supplemental receive timestamps,
ts_recv, which are used to construct our OHLCV aggregates. Most academic literature
avoids cross-venue arbitrage like this because timestamps from two different exchanges
are based on the different reference clocks that cannot be synced easily.
ts_recv mitigates this problem by providing a common reference time with
sub-microsecond accuracy between geographically-distant venues.
Configuration
Exchange and clearing fees can be found on CME and ICE's websites. Tick sizes and notional tick values can be obtained from instrument definitions.
# Backtest configuration
start = "2024-04-01"
end = "2024-05-15"
# Instrument-specific configuration
symbol_x = "CLM4"
symbol_y = "BRN FMN0024!"
tick_size_x = 0.01
tick_size_y = 0.01
tick_value_x = 10.0
tick_value_y = 10.0
fees_per_side_x = 0.70 # NYMEX corporate member fees
fees_per_side_y = 0.88
# Global configuration
commissions_per_side = 0.08
trading_days_count = 252 # Number of trading days in one year
# Model and monetization parameters
lookback = 100
entry_threshold = 1.5
exit_threshold = 0.5
p_threshold = 0.05
Data extraction
We'll define a function to download the data needed in this example.
def download_data(
dataset: str,
schema: str,
symbol: str,
start: str,
end: str | None = None,
) -> pd.DataFrame:
client = db.Historical(key="$YOUR_API_KEY")
data = client.timeseries.get_range(
dataset=dataset,
schema=schema,
symbols=symbol,
start=start,
end=end,
)
return data.to_df()
We'll fetch 1-minute OHLCV aggregates for ease of
demonstration, but you may specify schema="mbp-1" to use MBP-1
instead:
df_ohlcv_x = download_data("GLBX.MDP3", "ohlcv-1m", symbol_x, start, end)
df_ohlcv_y = download_data("IFEU.IMPACT", "ohlcv-1m", symbol_y, start, end)
df_ohlcv_x = df_ohlcv_x["close"].to_frame(name="x")
df_ohlcv_y = df_ohlcv_y["close"].to_frame(name="y")
df = df_ohlcv_x.join(df_ohlcv_y, how="outer").ffill()
Since OHLCV aggregates only print when there's a trade in the interval, you'll need
to use the .ffill() method to synchronize the two time series in cases
where one leg doesn't print.
Tip
Engle-Granger cointegration test
The basis of this strategy is to check that the residuals of a linear regression between the prices of the two instruments exhibits stationarity, also called the Engle-Granger two-step cointegration test. This implies that the two instruments' price series are cointegrated, and that the spread constructed based on this linear association of the two instruments' prices is stationary. In turn, this implies that the spread is mean-reverting.
Cointegration vs. correlation
Cointegration is preferred over correlation when constructing a pairs trade, since correlation doesn't apply to non-stationary time series, and financial instrument prices are typically non-stationary and trending. High correlation between such series can occur even without a meaningful relationship.
For instance, two price series which are trending in the same direction but diverging in the long run may exhibit a spurious, positive correlation.
On the other hand, cointegrated prices series may exhibit positive, negative, or even zero correlation over any period due to short-term fluctuations, but tend to track closely over the long run.
Implementation
The strategy is simple: First, over the lookback period (last 100 records), we run the cointegration test. If the two series are found to be cointegrated, then the coefficient of linear regression between the two series provides the ratio of the two instruments needed to construct the spread, also called the hedge ratio. We'll also compute the sample mean and standard deviation over this period.
Then, over the forward window (also 100 records), we compute the spread (residual) and normalize it by taking its z-score.
# Initialization
df["cointegrated"] = 0
df["residual"] = 0.0
df["zscore"] = 0.0
is_cointegrated = False
lr = LinearRegression()
for i in range(lookback, len(df), lookback):
x = df["x"].iloc[i - lookback:i].values.reshape(-1, 1)
y = df["y"].iloc[i - lookback:i].values.reshape(-1, 1)
if is_cointegrated:
# Compute and normalize signal on a forward window
x_new = df["x"].iloc[i:(i + lookback)].values.reshape(-1, 1)
y_new = df["y"].iloc[i:(i + lookback)].values.reshape(-1, 1)
spread_back = y - lr.coef_ * x
spread_forward = y_new - lr.coef_ * x_new
zscore = (spread_forward - spread_back.mean()) / spread_back.std()
df.iloc[i:(i + lookback), df.columns.get_loc("cointegrated")] = 1
df.iloc[i:(i + lookback), df.columns.get_loc("residual")] = spread_forward
df.iloc[i:(i + lookback), df.columns.get_loc("zscore")] = zscore
_, p, _ = coint(x, y)
is_cointegrated = p < p_threshold
lr.fit(x, y)
If the normalized residual is negative, it means the instrument associated with y is underpriced, i.e. we'll buy y and sell x to monetize the prediction that their prices will converge in the future. Conversely, if the normalized residual is positive, we'll sell y and buy x.
Since the two products have a similar notional value and futures have large minimum
order size, we'll trade a static hedge ratio of 1. If you're modifying this strategy to
trade stocks or ETFs or products that have significant differences in volatility or
notional value, you should consider using the dynamic hedge ratio lr.coef_ to scale
your position.
TipThe hedge ratio
lr.coef_may be negative. This regularly occurs, for instance, if one leg of the pair is an inverse ETF.
# Standardized residual is negative => y is underpriced => sell x, buy y
# Standardized residual is positive => y is overpriced => buy x, sell y
df["position_y"] = np.select([df["zscore"] < -entry_threshold, df["zscore"] > entry_threshold], [1, -1])
df["position_x"] = -df["position_y"]
It's common to specify a score-based or time-based exit condition. For example, we can exit the position when the spread converges to within +/-0.5 standard deviations. This has the effect of longer holding periods and lower transaction costs.
# Exit positions when z-score crosses +/- exit_threshold
hold_y_long = np.where(df["zscore"] <= -exit_threshold, 1, 0)
hold_y_short = np.where(df["zscore"] >= exit_threshold, 1, 0)
# Carry forward positions until exit condition is met
df["position_y"] = df["position_y"].mask((df["position_y"].shift() == -1) & (hold_y_short == 1), -1)
df["position_y"] = df["position_y"].mask((df["position_y"].shift() == 1) & (hold_y_long == 1), 1)
df["position_x"] = -df["position_y"]
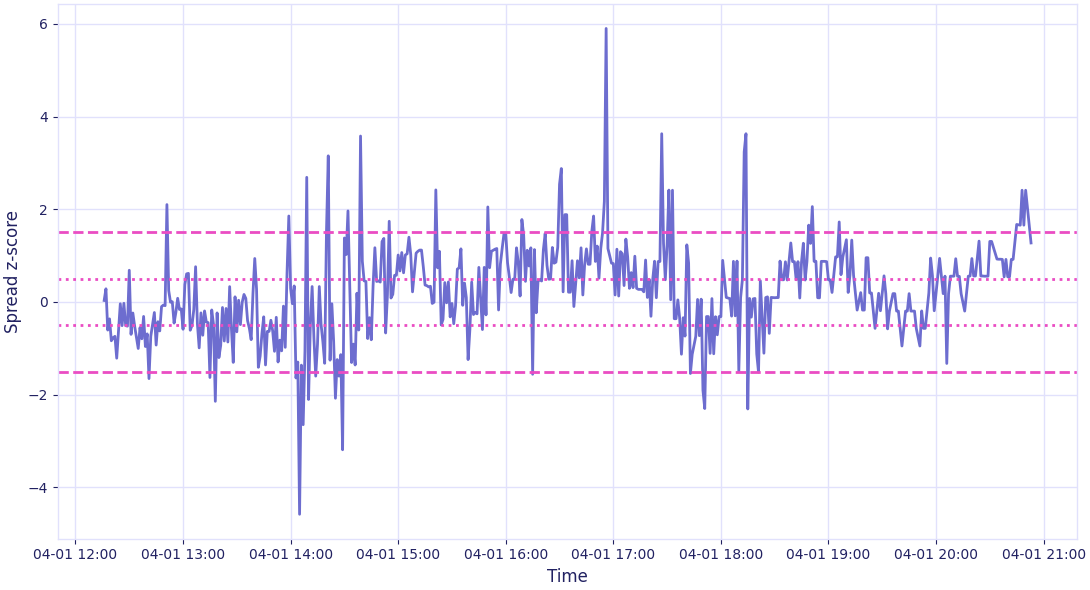
Here's a visualization of the strategy. The outer dashed lines show the entry conditions while the inner dashed lines show the exit conditions:
Estimating slippage
Exact instantaneous slippage from crossing the spread can be calculated using MBP-1 data and execution timestamps from the backtest. In the interest of time, you can gauge the viability of the strategy by applying a constant spread cost per contract side. This is typically assumed to be half a tick or one tick for liquid futures, but we can also estimate it quickly from a small slice of MBP-1 data:
# Estimate slippage
df_mbp1_x = download_data("GLBX.MDP3", "mbp-1", symbol_x, start)
df_mbp1_y = download_data("IFEU.IMPACT", "mbp-1", symbol_y, start)
avg_spread_x = (df_mbp1_x["ask_px_00"] - df_mbp1_x["bid_px_00"]).mean()
avg_spread_y = (df_mbp1_y["ask_px_00"] - df_mbp1_y["bid_px_00"]).mean()
Backtest
We can now compute the gross PnL and transaction costs:
# Compute backtest results
df["pnl_x"] = df["position_x"].shift() * df["x"].diff() / tick_size_x * tick_value_x
df["pnl_y"] = df["position_y"].shift() * df["y"].diff() / tick_size_y * tick_value_y
df["volume_x"] = df["position_x"].diff().abs()
df["volume_y"] = df["position_y"].diff().abs()
df["tcost"] = (
df["volume_x"] * fees_per_side_x + df["volume_y"] * fees_per_side_y + # Exchange fees
(df["volume_x"] + df["volume_y"]) * commissions_per_side + # Commissions
(df["volume_x"] * avg_spread_x / tick_size_x / 2 * tick_value_x) + # Slippage
(df["volume_y"] * avg_spread_y / tick_size_y / 2 * tick_value_y) # Slippage
)
df["gross_pnl"] = df["pnl_x"] + df["pnl_y"]
df["net_pnl"] = df["gross_pnl"] - df["tcost"]
Results
# Plot and print results
daily_pnl = df["net_pnl"].groupby(df.index.date).sum()
sr = daily_pnl.mean() / daily_pnl.std() * np.sqrt(trading_days_count)
print(f"Sharpe ratio: {sr:.2f}")
df[["gross_pnl", "net_pnl", "tcost"]].cumsum().plot(xlabel="Date", ylabel="PnL (USD)", title="Trading results")
plt.legend(["Gross PnL", "Net PnL", "t-cost"])
plt.show()
Sharpe ratio: 8.57

InfoThe full code example can be found on our GitHub here.

Practical considerations and improvements
This tutorial is kept intentionally short using a simple vectorized implementation. Ideally, you should use MBP-1 data with an event-driven backtest loop that incorporates the delays between your system and the exchange gateways. This can be done using the market replay method.
This strategy is very sensitive to slippage and the exact expiration month that's traded; non-lead month contracts will have wider spreads which can make the strategy infeasible.
We assumed exchange fees and commissions that are realistic for a medium-sized trading firm or a team within a larger firm that's already a CME member firm. In practice, achieving similar rates requires a NYMEX 106.J corporate membership and thousands of contract sides executed per day.
Scaling up to larger trade sizes will significantly expand the strategy's state machine, since you'll have to handle partial executions and different sizes on each leg of the spread to achieve optimal hedge ratio. MBP-1 data can also inform trade sizing.
We introduced a few free model and monetization parameters, namely
LOOKBACK, ENTRY_THRESHOLD, EXIT_THRESHOLD. These can be optimized
using any hyperparameter tuning method (e.g. grid search) and cross-validated.
There are also a few common variations of this strategy to consider:
- Basket trading by constructing combinations of more than two instruments, using another procedure such as the Johansen test.
- Calibrating an Ornstein-Uhlenbeck process, which gives a parametric model for time-based exit.
- Using total least squares instead of ordinary least squares to determine the hedge ratio.
- Scanning a wide universe systematically for cointegrated pairs, to discover unintuitive relationships. However, this runs the risk of poor generalization if too many pairs are tested. Dimensionality reduction methods like PCA can improve the search and generalization error.
Further reading
Alexander, C. (2008). Market Risk Analysis: Practical Financial Econometrics (Vol. 2). Wiley.
Tsay, R. S. (2010). Analysis of Financial Time Series (3rd edition). Wiley.
Engle, R. F., & Granger, C. W. J. (1987). Co-integration and error correction: Representation, estimation, and testing. Econometrica, 55(2), 251-276.